2026年4月、OpenAIからGPT-5.5が発表されました。Terminal-Bench 82.7%/GDPval 84.9%/OSWorld 78.7%という公表値は、エージェント型コーディングの実用域にモデルが入ってきたことを示唆しており、発表直後から開発者コミュニティでも反響が大きい一本になっています。本記事ではOpenAI公式の発表と日本語圏の一次解説(@catshun_さん、@itnavi2022さんのnote)を突き合わせながら、GPT-5.5をエンジニアが実務でどう使い倒すか、Claude Opus 4.7との棲み分け、プロンプト戦略のアップデート、そして個人エンジニアの市場価値にどう効いてくるかを、編集部の実務視点で一緒に整理していきます。
この記事の要点
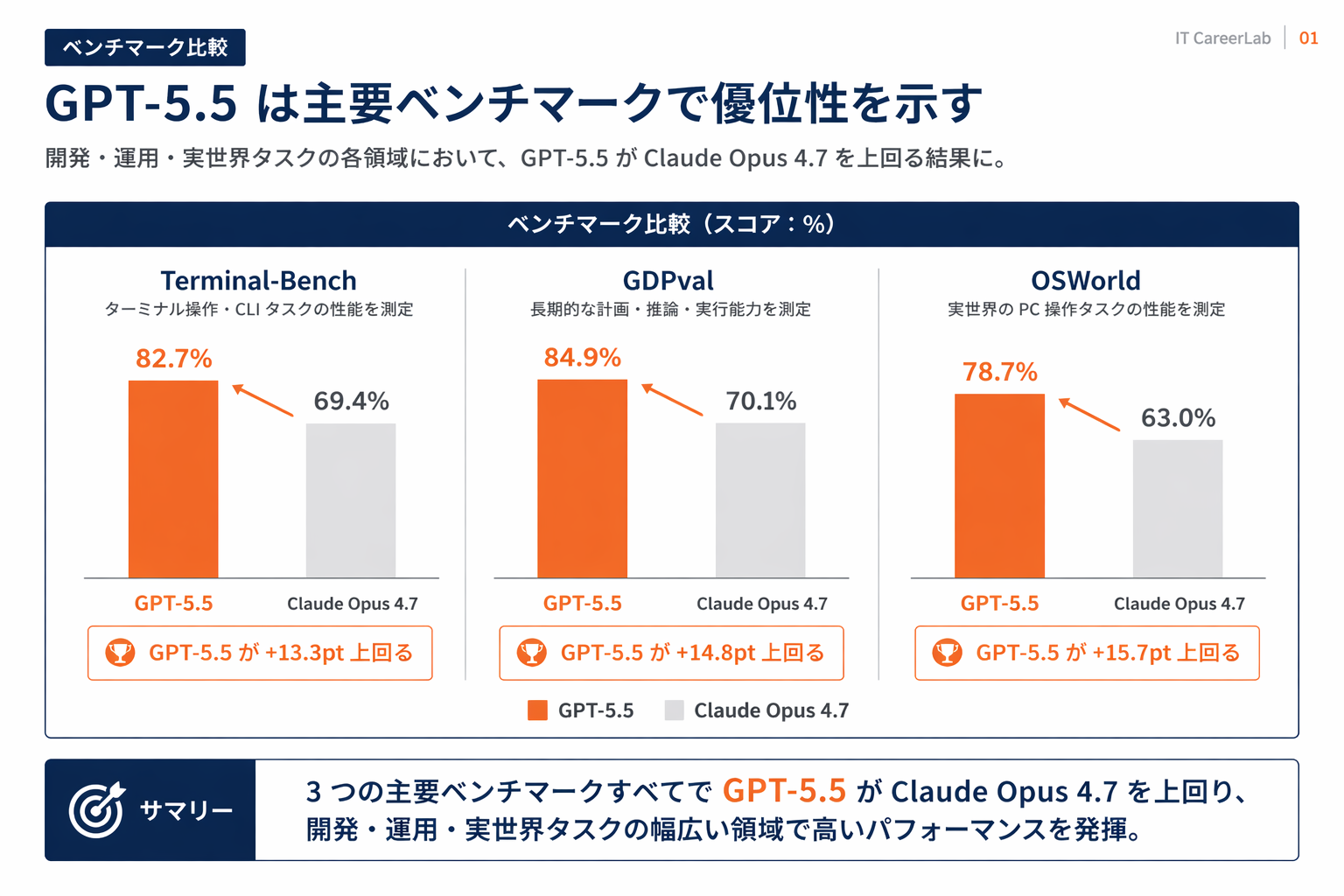
- GPT-5.5はOpenAIが2026年4月に発表したモデルで、Terminal-Bench 82.7%/GDPval 84.9%/OSWorld 78.7%といった高いベンチマーク値が公表されています(OpenAI公式)。
- 設計思想としては「エージェント型コーディング」と「長尺タスクでの自走」に最適化されていると発表されており、Claude Opus 4.7とは得意領域が部分的に重なりつつも棲み分けが可能なモデルとして位置づけられます。
- 実務で効くのは、長尺リファクタ/エージェント型タスク自動化/大規模コード探索の3領域。一方で、リアルタイム対話・軽量分類・数日スケールの自律エージェントは、GPT-5.5を前面に置かない設計が安全です。
- プロンプト設計は推論モデル時代の原則(CoT指示不要/JSON要求先頭配置/短いself-check/思考予算の段階制御)が継続します。モデル特化のテクニックに走るより、能力スタックの原則を積み上げるほうが長持ちするはずです。
- 編集部の考察として、GPT-5.5は「AIコーディングを使いこなせる個人エンジニア」の市場価値をさらに押し上げる方向に働くと見ています。ただし、モデル名を触れることより、アウトカムを語れることが評価軸であり続ける点は強調しておきたいところです。
GPT-5.5 の概要と公式ベンチマーク
GPT-5.5は、OpenAIが2026年4月に発表したフロンティアモデルです。公式発表によれば、GPT-5系で培われた推論モデルのアーキテクチャを踏襲しつつ、特にエージェント型タスク(ターミナル操作・ブラウザ操作・長尺コード編集)での性能改善に重心が置かれていると説明されています。
公表されている主要ベンチマーク
公式発表で示された代表的な数値を整理すると、以下の通りです。いずれも「〜と発表されています」の形で受け取り、自社ドメインでの検証は別途必要になります。
- Terminal-Bench: 82.7% — ターミナル環境でのエージェント的タスク遂行能力。ファイル操作・ビルド・デバッグ・環境構築など、CLIを介した実務操作をどれだけこなせるかを測る評価と発表されています。
- GDPval: 84.9% — 経済活動に紐づく実務タスクをモデルがどれだけ代替・支援できるかを測る評価群として公表されています。
- OSWorld: 78.7% — OS(デスクトップ)操作を介したエージェントタスクの評価。アプリケーションを跨いだ操作連鎖を捌けるかを見るベンチと発表されています。
- SWE-bench Verified — GitHubの実issueに対してパッチを生成し既存テストが通るかを測るコーディング系ベンチ。GPT-5.5もこの領域で高いスコアが示されており、Claude Opus 4.7と近接する領域で僅差の勝負になっていると発表されています(SWE-bench公式)。
コスト構造と提供経路
OpenAI公式の整理によれば、GPT-5.5はAPIおよびChatGPT経由で提供され、推論モデルとしての思考トークン課金構造が継続していると発表されています。具体の単価表は公式の料金ページが最新の一次情報になるため、本記事では数値を固定せず「入力・出力・思考の3系統で積み上がる」という構造的な理解を優先します。この構造自体は推論モデル時代のプロンプト設計で扱った見立てと整合しており、運用設計は大きく変わらないという肌感です。
個人開発者向けの視点では、ChatGPTのPlus/Pro相当のUI経由でまず挙動を体感し、本番アプリに組み込む段階でAPIに移す——この二段構えが現実的だと思います。APIから叩くとコストの見えない膨張が起きやすいので、思考予算の上限を早い段階で切ってから範囲を広げるのがおすすめです。
発表の読みどころ(@catshun_さん/@itnavi2022さんの整理より)
日本語圏の一次解説として、@catshun_さんの「【備忘】GPT-5.5」と@itnavi2022さんの「GPT-5.5を技術者目線で解剖する」は読み応えのある記事です。両者に共通している読み解きとしては、「GPT-5.5は単に精度が上がったモデルというより、エージェント的な自走を前提とした設計が一段深まったモデル」という論点が挙げられます。編集部としても、この視座で読むと実務での使い方が整理しやすいと感じました。
GPT-5.5 と Claude Opus 4.7 の棲み分け
2026年4月時点で、ハイエンドの推論モデルとしてはGPT-5.5とAnthropicのClaude Opus 4.7が並走する構図になっています。両者をどう使い分けるか、ユースケース別に整理してみます。
| ユースケース | 推奨1位 | 推奨2位 | 理由 |
|---|---|---|---|
| ターミナル操作を伴うエージェント | GPT-5.5 | Claude Opus 4.7 | Terminal-Bench 82.7%/OSWorld 78.7%と発表されている領域 |
| 長尺コードの対話的リファクタ | Claude Opus 4.7 | GPT-5.5 | 長文での構造維持・破壊少なさで評価が安定している傾向 |
| 大規模コード探索・仕様把握 | GPT-5.5 | Claude Opus 4.7 | エージェント的に複数ツールを跨ぐ自走タスクで優位と発表 |
| 日本語ドキュメント生成 | Claude Opus 4.7 | GPT-5.5 | 敬語・含意・トーンの扱いで体感品質が高い傾向 |
| JSON Schema厳守の構造化出力 | GPT-5.5 | Claude Opus 4.7 | ツール呼び出しの頑健さでGPT系が選ばれやすい |
| 契約書・法務系のレビュー | Claude Opus 4.7 | GPT-5.5 | 長文の前提保持とニュアンス処理 |
ここで大事にしたいのは、表の順位はあくまで傾向として受け取ってほしい点です。公式ベンチは僅差になっている領域が多く、自社ユースケースで並列A/Bを走らせてみると順位が入れ替わることは十分にあり得ます。編集部の実務肌感としては、「GPT-5.5とClaude Opus 4.7のどちらを選ぶか」より「どの時間帯・どのユースケースでどちらを呼び出すか」の設計が効くと感じています。
実務で GPT-5.5 が効く3ユースケース
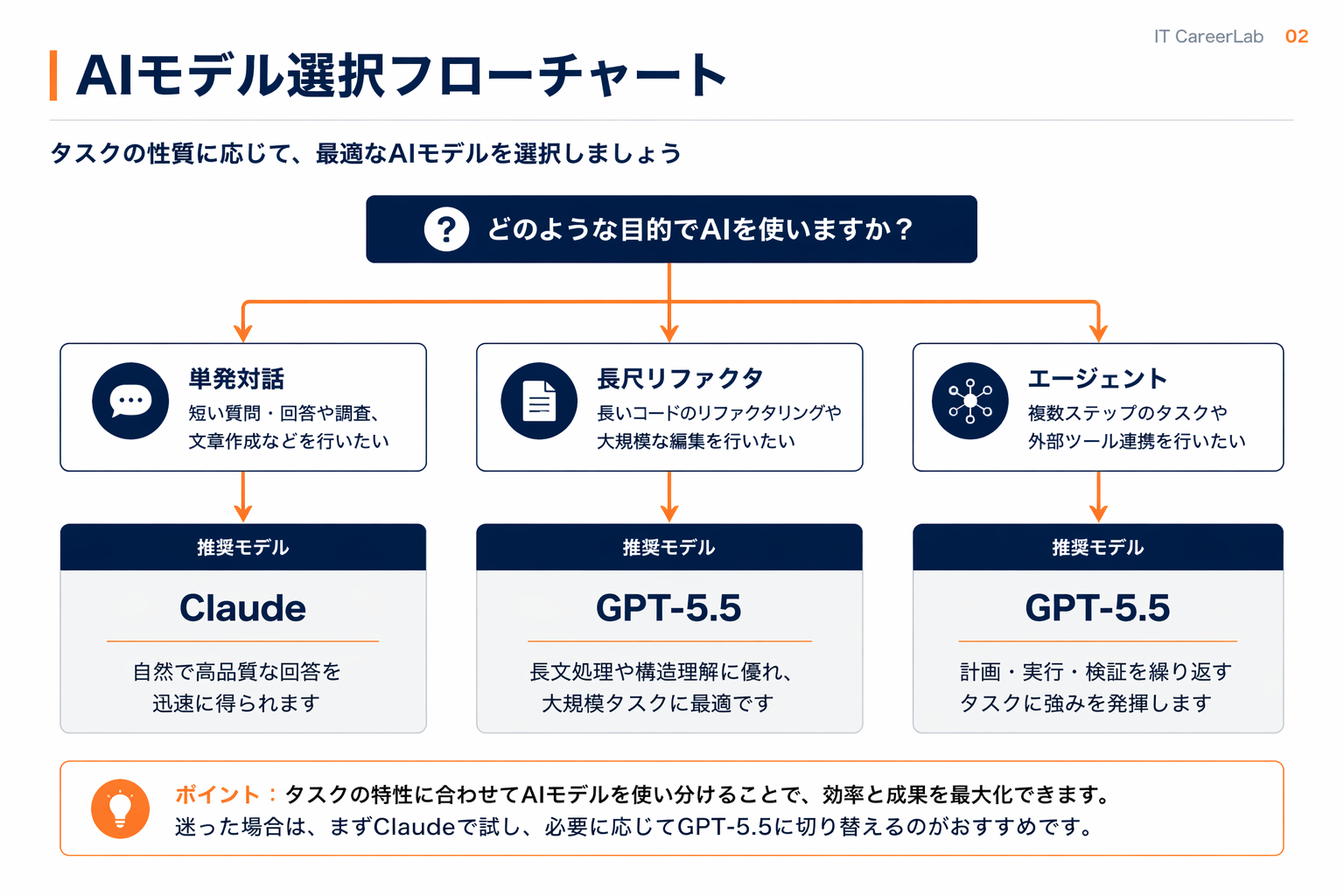
ベンチ数値と実運用の所感を踏まえて、GPT-5.5が特に効きやすい3つのユースケースを掘り下げます。
ユースケース1:長尺リファクタ(仕様変更を伴う大規模修正)
レガシーなモノリスや長年運用されているAPIに仕様変更を入れる場面では、1ファイル完結ではなく10〜30ファイルを跨ぐ修正が発生します。こうした長尺タスクでは、ファイル間の整合性を保ちながら、テストの追従まで含めて一気通貫で回せるかが勝負どころです。GPT-5.5はエージェント的にファイル読み書き・差分適用・テスト実行を連鎖させる設計との相性が良いと発表されており、Terminal-Benchの高スコアもこの文脈で実感値と結びつきやすい領域だと感じています。
ただし、長尺タスクで自走させる際はチェックポイント設計が肝心で、「30分走らせて結果を全レビュー」より「10分ごとにセーブポイントを取って人が確認」のほうがトラブル回収コストが下がる、というのが編集部の肌感です。
ユースケース2:エージェント型タスク自動化(CI連携・定型作業)
Pull Requestのレビュー自動化、依存関係の定期アップデート、セキュリティパッチ適用、ドキュメントの更新追従——こうした「定型的だが毎回少しずつ文脈が違う」タスクは、エージェント型の得意領域です。GPT-5.5はツール呼び出しの頑健さが発表上強調されており、CIパイプラインの中にエージェントを組み込む設計とも相性が良いと見ています。
導入時の落とし穴は、最大ステップ数と最大トークン数の上限設計をサボること。無限ループやコスト暴走は推論モデル共通のリスクなので、エージェントフレームワークの実装詳細はマルチエージェントSDK比較で整理した観点を必ず踏んでおきたいところです。
ユースケース3:大規模コード探索・仕様把握
新しく参画したプロジェクトで、数十万行のリポジトリの全体像を掴む場面。これは従来「読み込みながらメモを作る」という属人的な作業でしたが、GPT-5.5にエージェント的にgrep・ファイル読み込み・依存関係解析をさせて、構造を要約してもらう使い方が現実的になってきました。編集部でも試してみたところ、ドメインモデルの境界を言語化してもらったり、主要なアーキテクチャ決定の痕跡(古いコメント・deprecatedフラグ・テストの抜け)を拾い上げてもらう用途で手応えがありました。
この使い方は、MCP(Model Context Protocol)経由でコードベースへのアクセスを標準化しておくと再現性が上がります。実装の入口はMCP実装ハンズオンにまとめているので併読してみてください。
実務で避けるべきパターン
GPT-5.5は強力ですが、何にでも効く万能モデルというわけではありません。むしろ「使うべきでない場面」を先に言語化しておくほうが、実務でのコストと事故を減らせます。
避けるべき1:リアルタイム対話・インライン補完
推論モデルは原理的にレイテンシが伸びやすく、1秒以内の応答を期待するUX(チャットの最初の1レス、エディタのインライン補完など)には向きません。こうしたユースケースには、GPT-5 miniやGPT-5 nano相当の軽量モデル、あるいはClaude Sonnet系・Gemini Flash系を前面に置き、推論モデルは「必要に応じてバックグラウンドで呼び出す」構成が素直です。
避けるべき2:軽量分類・短い要約
単純な感情分類、メール振り分け、一文要約のような軽量タスクにGPT-5.5を使うのは、思考トークンのコストが見合いません。これらは軽量モデルで十分で、推論モデルを使っても体感精度の向上は微々たるものというのが実務の肌感です。コスト最適化のためには、「簡単な質問は軽量モデル/難しい質問だけ推論モデルにルーティング」の2段構えが基本設計になります。
避けるべき3:数日スケールの自律エージェント
「1週間かけて新機能を自動開発してもらう」といった超長尺の自律エージェントは、2026年時点でもハルシネーションの累積・コスト暴走・ループ制御の難度が残る領域です。GPT-5.5の精度が上がっても、人間のレビューポイントを数時間単位で挟まない設計は事故率が下がりきりません。編集部の立場としては、エージェントの責任範囲を狭く切ること、チェックポイントを細かく取ること、失敗時のフォールバックを明示することを徹底したいところです。
避けるべき4:コスト感覚を持たずに本番投入
GPT-5.5の実効コストは、思考トークンを含めると見かけの単価の数倍になる可能性がある——この構造は推論モデル時代のプロンプト設計で整理したGPT-5.4世代と共通です。想定ワークロードに対するコスト試算をせずに本番投入すると、月末の請求で事故が起きがちです。思考予算(reasoning_effort)の上限を最小値から始めて段階的に上げるのが安全側の運用だと思っています。
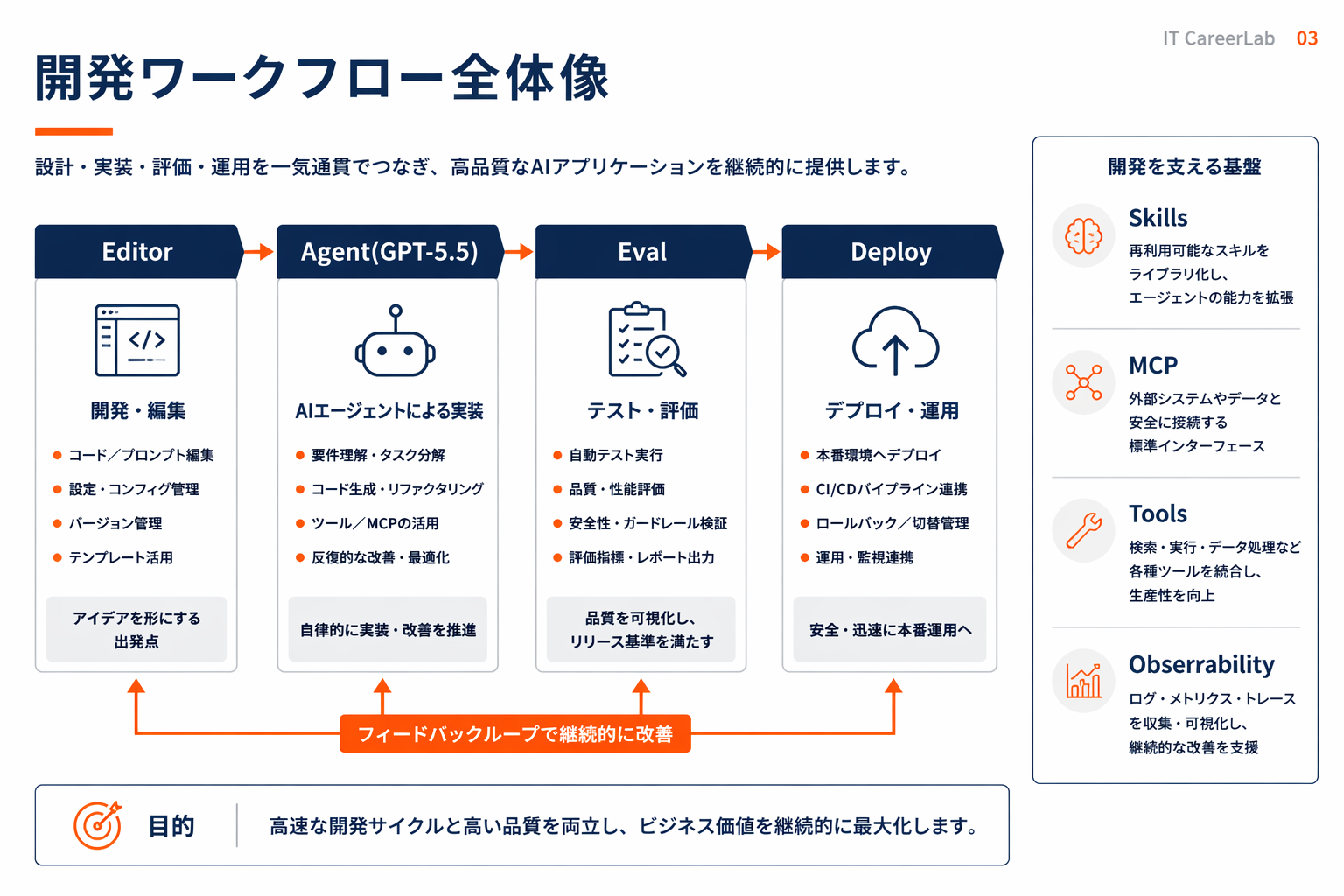
開発ワークフローへの組み込み方(Claude Code / Cursor / Codex CLI との使い分け)
GPT-5.5を実際の開発フローに組み込むとき、どのツールをフロントに置くかで体感が大きく変わります。2026年4月時点の主要クライアントと、GPT-5.5との相性を整理してみます。
Claude Code
Anthropicが提供するコマンドライン型のコーディングアシスタント。標準ではClaude系モデルが前提ですが、MCP経由で他プロバイダのモデルを外部ツールとして呼び出す設計は可能です。編集部の実務では、対話的な設計議論・コードレビュー・テスト追加はClaude Codeで回し、長尺のエージェントタスクは別途GPT-5.5のAPIに投げる、という棲み分けが落ち着きやすいと感じています。
Cursor
CursorはIDE型のエディタで、複数プロバイダのモデルをスイッチしながら使える設計が特徴です。GPT-5.5をCursor上で選択して、タスクのステップごとに呼び出すモデルを切り替える運用は相性が良いはずです。エージェント機能(Cursor Agent/Composer)と組み合わせると、エディタから離れずに長尺タスクを回せる体験が得られます。
Codex CLI(OpenAI公式)
OpenAI公式のCLIクライアントで、GPT-5.5とネイティブに連携する設計になっています。ターミナル操作を伴うエージェントタスクとの親和性は最も高く、Terminal-Bench 82.7%の実感値を得やすいのはこの経路だと感じています。CI連携や定型作業の自動化を組むとき、最初に検討したいクライアントです。
使い分けの基本原則
3つのクライアントをすべて使いこなす必要はなく、自分の主戦場に合わせて1〜2本を選ぶ発想で十分です。編集部の推奨は以下の通り。
- 対話的なコード書き:Claude Code or Cursor(Claude Opus 4.7を主軸)
- エージェント的な自走タスク:Codex CLI or Cursor Agent(GPT-5.5を主軸)
- コードベースの大規模探索:Cursor(モデル切り替えでタスクごとに最適化)
AIコーディングツールのスキル全体像はAIエンジニアのキャリア戦略でも扱っています。特定ツールに固執するより、複数のクライアントを触って切り替え判断ができる状態にしておくほうが、長期的には市場価値につながると見ています。
プロンプト戦略のアップデート(推論モデル時代の書き方)
GPT-5.5は推論モデルの系譜なので、プロンプト設計の基本原則は推論モデル時代のプロンプト設計で扱った方向性が継続します。改めて、GPT-5.5を使う前提で押さえておきたい原則を整理します。
原則1:Chain-of-Thought の明示指示は不要
「ステップバイステップで考えて」「まず推論してから答えて」といった外部CoTの指示は、推論モデルでは冗長になります。GPT-5.5は内部で思考トークンを生成するので、外側にCoTを書くと思考が二重化し、出力が肥大化したり形式が崩れたりする原因になります。
原則2:役割・入力・期待出力・禁止事項のセクション分け
プロンプトの構造化は、推論モデル時代でも最も効果が安定する基本テクニックです。XMLタグや見出しで明示的に区切ると、GPT-5.5も素直に構造を汲んでくれます。JSON形式を要求する場合は、プロンプトの先頭にスキーマを置くのが鉄則です。
原則3:short self-check を添える
「出力前に次の観点でセルフチェック:1) 事実関係、2) 形式、3) 矛盾」のような短い検算指示は、GPT-5.5でも効きます。ただし検算観点を長く書きすぎると、本体の推論が薄くなるので3〜5項目に留めるのが目安です。
原則4:reasoning_effort を段階的に使う
OpenAI API ではreasoning_effortをlow/medium/highで指定できる設計が浸透しています。簡単なタスクに最大予算を当てるとコストとレイテンシだけが増えるので、まずlowで試し、精度が足りなければ段階的に上げる運用が基本です。
原則5:few-shot は最小限
従来モデルで有効だった「十数例のfew-shot」は、推論モデルでは逆効果になる局面があります。GPT-5.5でも2〜3例で足りるなら3例まで、それ以上は「スキーマ説明+1例」で十分なことが多いです。
最小コード例:GPT-5.5 API 呼び出し
以下は2026年4月時点のSDK挙動を前提にした最小例です。パラメータ名は版によって揺れる可能性があるため、本番採用前には最新の公式ドキュメントを参照してください。
import OpenAI from "openai";
const client = new OpenAI();
const res = await client.responses.create({
model: "gpt-5.5",
input: "このリポジトリの主要なドメインモデルの境界を、3つの責務に分けて説明してください。",
reasoning: { effort: "medium" },
text: {
format: {
type: "json_schema",
name: "domain_boundaries",
schema: {
type: "object",
properties: {
boundaries: {
type: "array",
items: {
type: "object",
properties: {
name: { type: "string" },
responsibility: { type: "string" },
owned_modules: { type: "array", items: { type: "string" } },
},
required: ["name", "responsibility", "owned_modules"],
additionalProperties: false,
},
},
},
required: ["boundaries"],
additionalProperties: false,
},
strict: true,
},
},
});このパターンはGPT-5.4世代とほぼ同じ構造で、設計資産をそのまま持ち込める点がGPT-5.5に乗り換える際の導入コストを下げてくれます。
編集部の考察 — GPT-5.5 が個人エンジニアの市場価値に与える影響
ここからは編集部の考察として、GPT-5.5の登場が個人エンジニアの市場価値にどう効いてくるかを整理してみます。客観情報ではなく筆者の解釈である点を明示した上で、読者の判断材料として受け取っていただければ嬉しいです。
考察1:コーディング単体のアウトプット量は「AI使用者」に寄っていく
Terminal-Bench 82.7%という数値を素直に読むと、ターミナル操作を伴う定型的なコーディング作業の生産性は、AIを使いこなせる人と使わない人でさらに差がつく方向に進むと見ています。「AIは補助ツール」というスタンスで距離を置いてきた層にとっては、ここから数年で実感するギャップが一段大きくなる局面かもしれません。とはいえ、編集部としては過度に煽りたくはなくて、今からでも触り始めれば遅くはない、というのが率直な見立てです。
考察2:評価軸は「モデルを使えること」から「アウトカムを出せること」へ
一方で、GPT-5.5を触れる人が増えれば増えるほど、「使えること」自体の希少性は相対的に下がっていきます。市場で評価され続けるためには、モデルを使ってどんなアウトカム(業務時間の削減、品質の改善、新しい体験の実装)を出したかを語れることが本質的な差別化になるはずです。ポートフォリオや職務経歴書で「GPT-5.5を触りました」で止めるのではなく、「GPT-5.5を使ってXXを自動化し、Before/Afterをこう計測した」まで書ける状態を目指したいところです。可視化のテンプレはITエンジニアのポートフォリオガイドでも整理しています。
考察3:AIネイティブなエンジニアという新しい標準
2026年のITエンジニア市場では、AI Builderのような新しい職種概念が議論され始めています。GPT-5.5のような高性能モデルが出揃うことで、「AIを前提にアウトカムを10倍にする」という職種の実質がさらに具体化していく方向に見えます。個人エンジニアとしては、モデル個別の追いかけっこより、エージェント設計・評価セット運用・コスト最適化・チェンジマネジメントといった横断スキルを積み上げておくほうが、呼称が変わっても市場価値が残りやすいと感じています。
考察4:ハイクラス転職市場での評価
ハイクラス帯の転職市場では、LLMアプリの実運用経験・エージェント設計・MCP統合・観測性・コスト最適化の5点セットで語れる人材の希少性が引き続き高い状態です。GPT-5.5の登場はこの傾向を加速させる方向に働くはずで、具体のポジションや年収レンジの肌感はハイクラスITエンジニア向け転職エージェント2026年版で整理したエージェント経由の情報収集が現実的です。自分の現在地を数値で測りたい方は市場価値診断もあわせて使ってみてください。
実践的な導入ロードマップ(今週 / 今月 / 3ヶ月)
ここまでの整理を踏まえて、少しでも手を動かし始めたい、と思った人向けに時間軸ごとの行動リストを並べてみます。全部やる必要はなく、自分の現在地に合うところから着手してみてください。
今週できること
- OpenAI公式のGPT-5.5発表記事を一次情報として通読する(公式リンク)。
- ChatGPT(Plus/Pro相当のUI)からGPT-5.5を呼び出し、自分の日常業務から1つタスクを渡して応答を観察する。
- Codex CLIまたはCursorをインストールし、ローカルで小さなタスクを1つ回してみる。
- 既存のプロンプト1本を「役割/入力/期待出力/禁止事項」の4セクションに書き直してみる。
今月できること
- 自社リポジトリまたは個人プロジェクトから10〜20件のタスクを切り出し、GPT-5.5 vs Claude Opus 4.7の並列A/Bを走らせる。評価軸は「正確さ」「形式遵守」「コスト」「レイテンシ」の4点。
- エージェント的なユースケース(PRレビュー自動化、依存更新、ドキュメント追従など)を1つ選び、小さく実装して本番に近い環境で検証する。
- 思考予算(
reasoning_effort)をlow/medium/highで切り替え、同一タスクのコスト・精度・レイテンシの3次元データを取る。 - MCPサーバーを1本書いてClaude CodeまたはCursorに接続し、ツール公開側の視点を得る(MCP実装ハンズオン参照)。
3ヶ月でできること
- 業務のワンフローをGPT-5.5前提で再設計し、Before/Afterを数値で取る。最低1件は社内共有資料にまとめる。
- LLMOps的な運用観点(プロンプトのバージョン管理、評価セットのCI化、コスト監視)を小さく実装してみる。
- ハルシネーション検出・コスト最適化・セキュリティレビューを含む、本番運用可能なアプリを1つ完走させる。
- ポートフォリオ・GitHubリポジトリ・社内発表資料のいずれかで、GPT-5.5を使ったアウトカムを外部に見せられる形に整える。GitHub経歴書ジェネレーターで可視化するのも有効です。
- ハイクラス転職の準備として、情報収集期からエージェントにレジュメを置いて市場反応を測る。エージェント選定はハイクラスITエンジニア向け転職エージェント2026年版を参考に。
参考リソース
- OpenAI「Introducing GPT-5.5」:https://openai.com/index/introducing-gpt-5-5/
- @catshun_「【備忘】GPT-5.5」note:https://note.com/catshun_/n/n87cbaec414fc
- @itnavi2022「GPT-5.5を技術者目線で解剖する」note:https://note.com/it_navi/n/n02cd5c857f96
- Anthropic Claude Opus 4.7 公式ドキュメント:https://docs.anthropic.com/
- SWE-bench 公式:https://www.swebench.com/
まとめ
- GPT-5.5はOpenAIが2026年4月に発表したモデルで、Terminal-Bench 82.7%/GDPval 84.9%/OSWorld 78.7%の公表値が示すとおり、エージェント型コーディングの実用域に入ってきたモデルとして位置づけられます。
- Claude Opus 4.7との関係は「乗り換え」ではなく「併用」が合理的。エージェント的な自走はGPT-5.5、対話的なコード磨きはClaude Opus 4.7、という時間帯・ユースケースでの切り替えが実務肌感として落ち着きやすい構図です。
- 実務で効くのは長尺リファクタ/エージェント型タスク自動化/大規模コード探索。一方で、リアルタイム対話・軽量分類・数日スケールの自律エージェントは、GPT-5.5を前面に置かない設計が安全です。
- プロンプト戦略は推論モデル時代の原則(CoT指示不要/JSON要求先頭配置/短いself-check/思考予算の段階制御)が継続。モデル特化のテクニックより能力スタックを積むほうが長持ちします。
- 編集部の考察として、GPT-5.5は個人エンジニアの市場価値にポジティブに効く一方、評価軸は「モデルを触れること」から「アウトカムを出せること」に移っていく見立てです。可視化・言語化・数値化を意識しておきたいところです。
- お読みいただきありがとうございました。公式発表と一次情報の両方にあたる習慣を保ちつつ、自社ドメインでの検証を積み重ねていくのが、長い目で見たときの近道だと思っています。
(本記事は2026年4月24日時点のOpenAI公式発表および日本語圏の一次解説、編集部の考察をもとにした見解です。ベンチマーク値は公式公表値をもとにしており、自社ユースケースで同等の精度を保証するものではありません。APIの単価・仕様・提供経路は各社公式情報の最新版をご確認ください。本サイトはTechGoのアフィリエイトパートナーであり、特定リンク経由の申込で収益が発生する場合があります)