
AIエンジニアの求人は、2023年以降の生成AIブームを経て職種の定義が大きく広がった。従来の機械学習エンジニア(MLE)に加え、LLMアプリ開発者、RAGエンジニア、Agent開発者、MLOpsエンジニア、プロンプトエンジニアなど、同じ「AIエンジニア」の肩書でも求められるスキルセットが大きく異なる。本記事では2026年時点のAIエンジニア市場を、職種分類・求人トレンド・年収レンジ・採用側が求めるスキル・キャリアルート別の移行戦略・学習ロードマップまでまとめて整理する。すでにエンジニアとして働いている人が、次の一歩としてAI領域をどう選ぶかを判断するための実務ガイドとして使ってほしい。
この記事でわかること
- 2026年時点で「AIエンジニア」と呼ばれる職種がどう分化しているか
- 生成AI前後でAI関連求人がどう変化してきたか(一般論ベース)
- ジュニア/ミドル/シニア/プリンシパル各レンジの年収の幅
- 採用側が今求めているスキル(LLM・RAG・Agent・評価設計・コスト最適化)
- Web/インフラ/データ分析からの移行戦略
- 3〜12ヶ月で組む学習ロードマップと、差がつくポートフォリオ要素
- AIエンジニアに強いエージェントの選び方と実務上の注意点
「AIエンジニア」は1つの職種ではない — 2026年の職種分類

求人票で「AIエンジニア」と書かれていても、実際の業務内容は大きく6タイプに分かれる。いずれを狙うかで、要求されるスキルセット・学習の順序・評価される経験が別物になるため、まずここを整理しておきたい。
1. ML基盤エンジニア(Machine Learning Engineer, MLE)
広告最適化、レコメンド、需要予測、異常検知といった「従来型ML」の設計・実装・運用を担う。scikit-learn/XGBoost/LightGBM/PyTorch を使いこなし、特徴量設計・モデル評価・A/Bテスト設計・オンライン推論の運用まで一気通貫で見る。データサイエンティストと重なる領域もあるが、MLEはプロダクションコード品質と運用責任までスコープに入る点が異なる。
2. LLMアプリケーションエンジニア
OpenAI/Anthropic/Google DeepMind の API を前提に、プロダクトに生成AI機能を組み込む。プロンプト設計、RAG(検索拡張生成)、ツール呼び出し、ガードレール、出力の品質評価までを扱う。Web/バックエンドエンジニアからの接続が比較的容易で、2024年以降最も求人数が伸びた領域の一つ。基盤モデルを自前で作るのではなく、「APIの制約と強みを理解し、プロダクトに載せ切る」設計力が問われる。
3. AIエージェント開発者(Agent Engineer)
ツール呼び出し・外部サービス連携・長期タスクの自動実行を前提に、LLMを複数ステップで動かすアプリケーションを設計する。MCP(Model Context Protocol)や各社のAgent SDKを踏まえた実装・状態管理・失敗時のリトライ・監査ログなど、「LLMが関わる長時間ジョブの信頼性」をどう担保するかが主な論点だ。実装の基礎はMCPハンズオン:stdio と Streamable HTTP をTypeScript SDKで実装するとマルチエージェントSDK比較で具体的に扱っている。
4. プロンプトエンジニア
2023〜2024年には独立職種として注目されたが、2026年時点では「アプリケーションエンジニア/LLMアプリエンジニアの一機能」として吸収されつつある。単独求人は大企業の限定ポジションや研究寄りのチームに残る程度で、多くの現場ではLLMアプリエンジニアや評価設計ロールの一部として扱われる。推論モデル時代のプロンプト設計はReasoningモデル時代のプロンプト設計にまとめている。
5. MLOpsエンジニア/ML基盤エンジニア
学習パイプライン、モデルレジストリ、推論インフラ、モニタリング、モデルの再学習・ロールバック、オンライン/オフライン特徴量ストアなどを設計・運用する。SRE・インフラ出身者からの接続が自然で、2026年時点でも採用側から最も「足りない」と言われ続けているレイヤーの一つだ。LLM時代に入ってからは、トークン消費のコスト最適化、推論GPUの占有設計、キャッシュ戦略も責任範囲に入ってきた。
6. データサイエンティスト(参考:AIエンジニアとの違い)
データサイエンティストは本来、ビジネス課題をデータ分析と統計モデリングで解くロールで、必ずしも本番システムの実装責任は持たない。AIエンジニア/MLEとの違いは「分析の成果物がレポート・仮説検証中心か、プロダクションシステム中心か」に近い。企業によって定義は揺らぐため、面談で「本番実装まで含むか/分析レポートで完結か」を必ず確認したい。
2026年のAIエンジニア求人トレンド
AIエンジニア関連の求人は、2022年末の生成AI登場を境に職種の広がりが急激に変わってきた。公表値のある統計に限らず、複数の転職サービスが公開する一般的な傾向としては、以下の流れが観察できる。
生成AI登場前(〜2022年)
- AIエンジニア=機械学習エンジニア/データサイエンティスト、という狭い定義が主流
- 求人は大企業の研究所・広告系・EC系レコメンドに集中
- 博士号・論文実績を要件に掲げる企業が目立ち、参入障壁が高かった
生成AI登場後(2023年〜)
- LLMアプリ・RAG・Agent など、アプリケーション実装側の求人が急増
- 中堅〜スタートアップからも「生成AI機能を自社プロダクトに組み込む」ポジションが増え、非研究系のWeb/バックエンド出身者の参入経路が広がった
- MLOps・推論基盤・コスト最適化など、インフラ側の専門職が不足気味で継続的に採用ニーズがある
- 「社内AIチーム立ち上げ」を任せるテックリード/プリンシパル級の求人が一定数継続
2026年時点の観察
- LLMアプリ・Agent領域は求人総数こそ高止まりする一方、企業側の要求レベルが上がり「生成AI APIを叩いた経験がある」だけでは評価されにくくなっている
- 「本番運用の経験」「評価設計」「コスト最適化」「ハルシネーション対策」を具体的に語れる候補者が優位
- LLM + 従来ML の組み合わせ(例:検索ランキングにLLMを補助的に使う構成)が増え、MLEとLLMアプリ両方の素養があると評価が上がる
- 外資系・グローバルテックの採用枠は依然として難易度が高いが、国内事業会社のAIチームは門戸が広がっている
経済産業省のIT人材需給調査や総務省情報通信白書でも、AI人材の需給ギャップは中長期的に継続するとの整理がなされており、市場の流れとしては追い風が続く見通しだ。ただし、個別企業のAIチームは採算圧迫のタイミングで縮小されることもあるため、マクロと個別をセットで見たい。
年収レンジの実際
AIエンジニアの年収は、職種・経験年数・企業フェーズによって振れ幅が大きい。以下は厚生労働省の賃金構造基本統計調査や主要転職サービスの公開レンジを踏まえた一般的な目安で、個別企業の提示額とは一致しない点にご留意いただきたい。
| レベル | 想定年収レンジ | 求められる経験 |
|---|---|---|
| ジュニア(1〜3年) | 概ね450万〜700万円程度 | LLM API/基本的なML実装/データ前処理/小規模プロダクト貢献 |
| ミドル(3〜7年) | 概ね700万〜1,100万円程度 | 本番運用経験/評価設計/1プロダクトを主担当/PR-FAQを書ける |
| シニア(7〜12年) | 概ね1,000万〜1,600万円程度 | 複数プロダクト横断/技術選定/スタッフレベルの影響力/採用面接の主担当 |
| プリンシパル/リード | 概ね1,400万〜2,000万円超 | 組織横断の技術戦略/AI基盤の設計責任/経営層との対話/外部発信 |
外資系AI企業や基盤モデル開発企業のオファーは、基本給に加えてRSU・サインオンが厚く、トータルコンペンセーションで国内企業を上回るケースが多い。基本給との比較ロジックは基本給 vs トータルコンペンセーションで整理しているので参照してほしい。自分の現在地を測るには年収レンジチェッカーが便利だ。
採用側が今求めているスキル
2026年時点でAIエンジニア採用の現場が重視しているのは、「最新モデルを使った経験」そのものよりも、プロダクトに載せ切る実装力と、運用を維持する設計力である。面接で具体的に問われやすい観点を5つに整理する。
1. LLMハンズオン経験
OpenAI/Anthropic/Google DeepMind などのAPIを実装で使った経験。単に「呼び出したことがある」ではなく、トークン制限への対処、構造化出力、ツール呼び出し、JSONモード、ストリーミング応答、失敗ハンドリングをどう設計したかまで語れるかが評価される。
2. RAG(検索拡張生成)の設計
ドキュメント分割戦略(チャンクサイズ・重複率)、埋め込みモデルの選定、ベクトルDB(pgvector/Weaviate/Qdrantなど)、ハイブリッド検索、Rerankerの使い分け、メタデータフィルタリング。回答品質が落ちたときの改善ループをどう回すかが、RAGエンジニアの実力を分ける。
3. AIエージェントの実装
ツール呼び出しの設計、長時間ジョブの状態管理、失敗時の復帰、監査ログ、コストの可視化。MCPの実装知識は2026年時点で評価軸に入ってきており、MCPハンズオンの内容を実装レベルで語れると差別化につながる。
4. 評価設計(Evaluation)
LLM/Agent系の評価は、従来のMLの正解ラベル型の評価とは異なる難しさがある。LLM-as-a-judgeの導入、goldenデータセット作成、失敗パターンの分類、回帰防止のテストハーネス化。採用側は「出力品質が下がったとき、どう気付くか」を具体的に問う。
5. コスト最適化
トークン消費のモニタリング、キャッシュ戦略、モデルの切り替え(Haiku/Flash系を使い分ける)、バッチ化、プロンプト圧縮。LLMアプリは機能を作るより本番運用で「利益を出す」ほうが難しく、コスト設計力は2026年に入って採用基準の上位に浮上している。
これらに加えて、システム設計の学習ロードマップとクラウド資格の優先順位で扱う基礎設計とインフラ運用の素養は、ミドル以上の評価を決定づける要因になりやすい。
キャリアルート別の移行戦略
Web/バックエンドエンジニア → LLMアプリ/Agent
最も移行コストが低いルート。API設計・非同期処理・状態管理・ログ設計の経験がそのままLLMアプリに活きる。まずは現職のプロダクトに生成AI機能を小さく組み込み、本番運用実績を1つ作ることを優先したい。社内活用の自動化ツール(議事録要約、社内FAQ)でもプロダクトグレードまで持っていけば立派なポートフォリオになる。移行の1年目で身に付けたいのは、プロンプト設計・RAG・評価設計の3点セットだ。
インフラ/SRE → MLOps
推論基盤・GPUスケジューリング・モデルのCI/CD・モニタリングといった領域は、SREの知見を直接持ち込める。Kubernetes、Argo Workflow、Kubeflow、Ray、GPU推論の運用経験があると、求人票の要件を満たすところまで一気に行ける。LLM時代に入ってからはトークン消費のモニタリング・レート制限・推論サーバのコールドスタート問題が新たな論点に加わっている。未経験領域にいきなり飛び込むのではなく、現職の中に「ML関連のインフラ業務」を作って実績化していくアプローチが堅実だ。
データ分析/BI → 機械学習エンジニア
データサイエンティスト寄りの分析経験を、プロダクションML実装まで拡張する動き。SQL・Python・データ前処理は資産として使いつつ、Docker/CI/CD/ワークフローエンジン(Airflow・Prefect)/MLライブラリの運用を足していく。1年以内に「自分が作ったモデルが本番で継続的に予測を返している状態」を1つ作れるかがターニングポイントになる。分析レポートで終わらせず、システム実装に踏み込むチャレンジをどう作るかがこのルートの鍵だ。
機械学習エンジニア → LLM時代のMLE
既にMLEとして働いている人は、従来MLの延長でLLMを自然に取り込める立ち位置にいる。注意したいのは「LLMを従来MLの置き換え先」と捉えすぎないこと。多くの現場では、LLMと従来MLを組み合わせたパイプライン(例:LLMで特徴量生成、XGBoostで最終判定)が現実解になっている。LLMを入れることで精度・コスト・レイテンシがどう変化するかを比較できる設計力が、2026年のシニアMLEの評価ポイントになる。
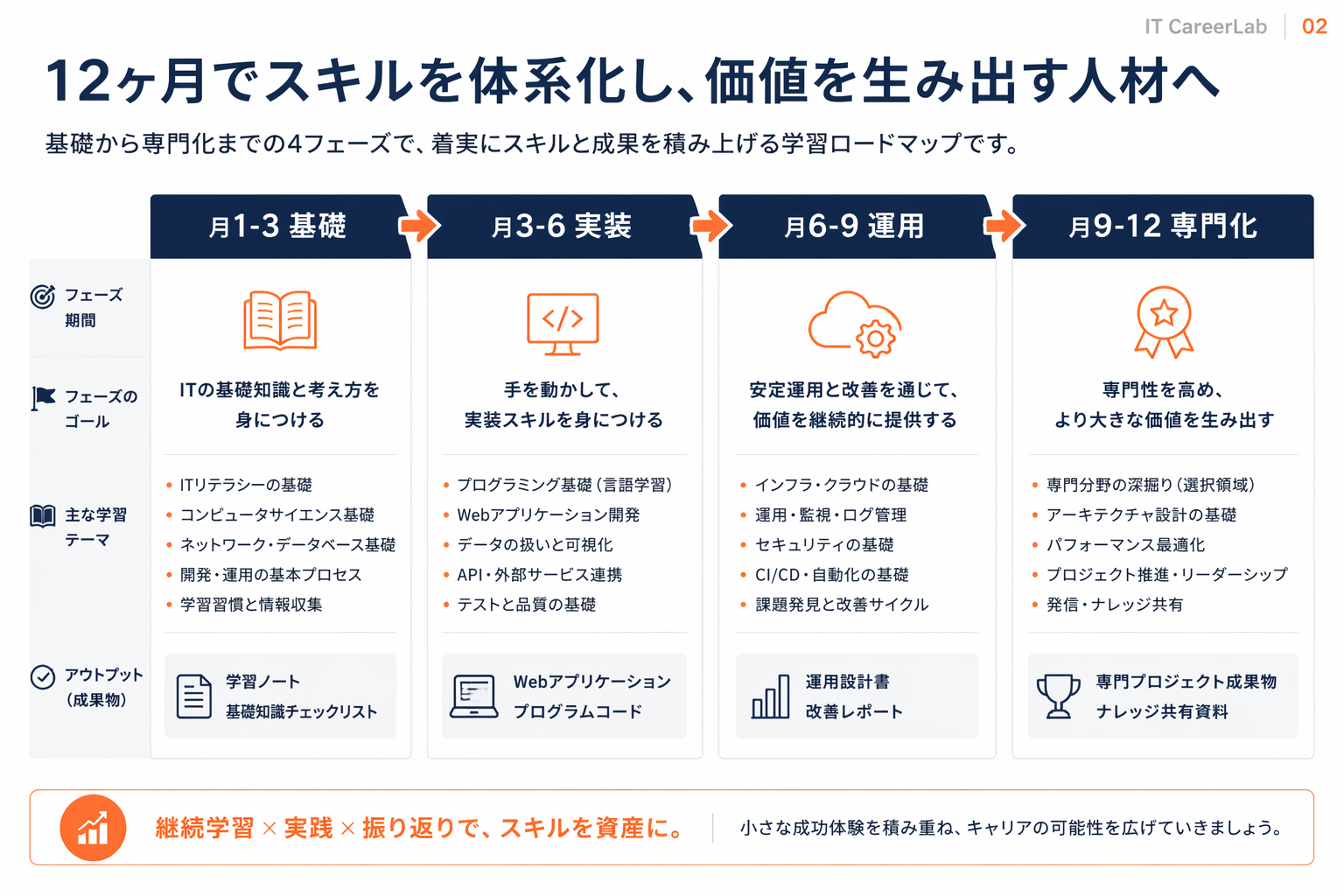
学習ロードマップ(3〜12ヶ月)
未経験から狙う場合も、隣接領域からの移行でも、以下の順序を踏むと投資効率が高い。
フェーズ1:基礎固め(1〜3ヶ月)
- Python・型ヒント・非同期処理の現場レベル習熟
- LLM APIの基本(OpenAI/Anthropic/Google DeepMindのSDK)
- プロンプトエンジニアリングの基本原則と失敗パターン
- 埋め込みモデルとベクトル検索の基礎
フェーズ2:RAGとAgent(3〜6ヶ月)
- RAGパイプラインを1つ自作(ドキュメント取り込み・分割・検索・生成・評価)
- LangChain/LlamaIndex/自前実装のいずれかで基礎を固める
- Agent SDKでツール呼び出し型Agentを1つ実装(マルチエージェントSDK比較参考)
- MCPで外部ツールを自作する(MCPハンズオン参考)
フェーズ3:本番運用とMLOps(6〜9ヶ月)
- 評価データセット作成、LLM-as-a-judge、回帰テストの設計
- トークン消費のモニタリング、アラート、コスト上限
- 推論サーバのレート制限、キャッシュ、フォールバック
- セキュリティ(プロンプトインジェクション対策、SSRF対策、PII除去)
フェーズ4:ポートフォリオ仕上げ(9〜12ヶ月)
- 1つ以上の公開プロジェクトをGitHubで継続メンテ
- ブログまたは登壇で「設計判断」を言語化
- 評価コードと運用ログを残し、再現性を示す
- 職務経歴書の数値化(職務経歴書テンプレート参考)
ポートフォリオで差が出る3要素
AIエンジニアの採用面接で、他候補と差がつく要素は3つに集約される。「動くもの」を作ること自体は最低ライン、そこからどう掘り下げるかが採用判断を分ける。
要素1:実タスクに沿った設計
チュートリアル写経ではなく、自分の仕事や身の回りの具体的な課題に落として作る。社内ナレッジの検索、議事録の要約と検索、技術記事のスクラップツール、学習支援のAgentなど、「誰のどんな困りごとを解くか」を先に定義した上で作ったものは、面接で話す深さが段違いになる。ドメイン設定の解像度が、エンジニアとしての成熟度を測る指標として見られている。
要素2:評価コード
LLMを使ったアプリは「動く」と「良い」の間に大きな隔たりがある。この差を埋めるのが評価コードだ。テストケース集を用意し、出力の品質を定量化し、プロンプト変更・モデル変更のたびに回帰を検出できる状態を作る。評価のコードが公開リポジトリに含まれているポートフォリオは、それだけで運用への意識が伝わる。
要素3:本番運用の知見
コスト、レイテンシ、エラーレート、ユーザー数、使用トークン数など、運用の実数値を持てる状態が理想。個人開発でもログ収集とダッシュボード化を組んでおくと、面接で「このプロンプト変更でトークン消費が30%減った」のような具体的な言及ができる。抽象的な成果よりも、具体的な運用メトリクスが評価される時代になっている。
AIエンジニアに強いエージェントの選び方
AI領域は専門性が高く、エージェントの力量差が大きいジャンルだ。担当者の技術理解度が低いと、見当違いの求人を大量に送られたり、企業との給与交渉で相場観がずれて損をするケースがある。選び方の実務的なポイントを整理する。
- IT特化型を軸に据える:総合型エージェントでもAI求人は扱うが、技術スタックや役割定義の解像度で差が出る。IT特化型または技術理解のあるハイクラス特化型を軸にするのが無難。
- 担当者の知識を面談で確認:初回面談で「LLMアプリ開発とMLEの求人の違い」「RAGとFine-tuningの選択基準」など、実務的な論点を投げて返答の質を測る。説明を聞き流して求人を送ってくるタイプは早めに担当変更を。
- 外資ITを視野に入れるならグローバル案件に強いエージェントを併用:外資系はエージェントと直接契約のヘッドハンター経由の両方で動くのが一般的。
- スカウト型でレンジ観察:ビズリーチなどスカウト型サービスは、レジュメを置くだけで自分の市場価値のレンジを観察できるため、AI領域の相場観を掴むのに向く。
- 交渉フェーズで交渉力のあるサービスを投入:オファー比較では、年収交渉設計が得意なエージェントを1社入れておくとトータル条件が改善しやすい。
エージェントの併用戦略はフェーズ別に設計するのが実務的で、情報収集期・選考直前・オファー比較期で使うサービスを変える。詳しくはハイクラスITエンジニア向け転職エージェント2026年版にフェーズ別の設計を記しているので合わせて参照してほしい。
まとめ
- 「AIエンジニア」は1つの職種ではなく、MLE/LLMアプリ/Agent/MLOps/データサイエンティストなど6系統に分化している。狙うレイヤーを先に決める。
- 2026年の求人トレンドは「APIを叩いた経験」から「本番運用・評価・コスト最適化」を語れる候補者優位へ移行している。
- 年収レンジは職種と経験で幅が大きいが、ミドル帯で700〜1,100万円、シニアで1,000〜1,600万円程度が一つの目安。
- Web/インフラ/データ分析からの移行は現実的で、それぞれ自分の強みを翻訳する戦略が鍵。
- 学習は3〜12ヶ月で基礎→RAG/Agent→運用→ポートフォリオの順に積むと投資効率が高い。
- 採用の差別化はポートフォリオの「実タスク/評価コード/運用知見」の3点に集約される。
(本記事は2026年4月時点の一般的な市場情報をもとにした編集部の見解です。年収レンジや求人動向は個別企業・時期により大きく変動します。本サイトはTechGoのアフィリエイトパートナーであり、リンク経由の申込で収益が発生する場合があります)


