2026年3月にOpenAIがAgents SDKを正式公開し、4月にはAnthropicがClaude 4.6と同時にClaude Agent SDKを、GoogleもADKを発表した。LangChain社のLangGraphを含めると、プロダクション利用に耐えるマルチエージェントSDKが主要3系統揃ったことになる。本記事では、設計の思想が大きく異なるこの3SDKを、実装者の視点から6つの観点で比較し、具体的なコードも並べて掲載する。どれを選ぶべきかの判断軸を整理したい。
エージェントSDK選定で本当に効く6つの観点
「どのSDKが最強か」という問いには意味がない。2026年4月時点ではどれもproduction readiness が高く、要件次第でベストは変わる。選定にあたって効いてくる観点は、実務経験上おおよそ以下の6つに集約される。
- オーケストレーション方式:エージェントをどう繋いで協調させるか。
- 状態永続化:会話・ワークフロー状態をどこにどう保存し、再開できるか。
- モデル柔軟性:どのLLMを選べるか、切り替えられるか。
- MCP統合:Model Context Protocolとの親和性の深さ。
- 観測性:トレース、メトリクス、デバッグのしやすさ。
- スケール/運用:long-runningやエラーハンドリング、コスト計測。
以下、それぞれの観点で3SDKの設計を順に見ていく。
観点1: オーケストレーション方式の違い
3SDKで最も設計思想が分かれるのがここだ。同じ「マルチエージェント」という言葉でも、実装モデルはまったく異なる。
LangGraph:有向グラフ+条件分岐
LangGraphは StateGraph にノード(エージェントやツール)とエッジ(遷移)を登録する、ワークフローエンジンに近いモデルだ。条件分岐も、同じノードに戻る循環も表現できる。リフレクションや自己修正ループのような「終了条件を満たすまで繰り返す」パターンを自然に書ける。
OpenAI Agents SDK:明示的ハンドオフ
OpenAI Agents SDKでは、エージェントが別のエージェントに処理を渡すときに handoff() を明示的に宣言する。エージェントは「自分で処理する」か「誰にhandoffするか」を LLM自身が選ぶ。ルーティングロジックがLLMの判断に寄るため、プロンプト設計でハンドオフ先を絞り込むのがコツになる。
Claude Agent SDK:ツール利用チェーン+サブエージェント
Claude Agent SDKは、親エージェントが1つの会話コンテキストを持ち、必要に応じてツールやサブエージェントを呼ぶ木構造として設計されている。サブエージェントは独立したコンテキストで動き、結果だけを親に返す。extended thinkingと組み合わさるため、親が長考してから子を呼ぶ、という流れを書きやすい。
観点2: 状態永続化と再開
エージェントは長時間走るケースが多く、途中で落ちたときに「どこから再開するか」が実運用では強く効く。3SDKのアプローチはまったく違う。
- LangGraph:PostgreSQL/SQLite の checkpointer がビルトインで、ノード単位の状態スナップショットを自動保存する。time-travel デバッグも可能で、特定ステップに戻って別の分岐を試す、といった使い方ができる。
- OpenAI Agents SDK:コンテキストは関数呼び出しスコープで揮発する前提。永続化したい場合は、ユーザ側でRedisやDBに書き出すラッパーを挟む。
- Claude Agent SDK:状態をMCPサーバのResourcesとして外に出す設計思想。SDK自身が状態を抱え込まず、MCPの共通プロトコル経由でファイル・DB・APIと接続する。
time-travel や人手レビューを挟むworkflowを作るなら LangGraph が一歩リードする。一方、外部システムと状態を共有したいケースでは、Claude SDKの「状態は全部MCP」という割り切りが綺麗に決まる。
参考までに、各SDKで最小のSupervisor(Orchestrator)を書いた場合のイメージを並べてみる。いずれも擬似コード寄りだが、書き味の違いが伝わると思う。
# LangGraph(Python): StateGraphでノードを繋ぐ
from langgraph.graph import StateGraph, END
from langgraph.checkpoint.postgres import PostgresSaver
graph = StateGraph(AgentState)
graph.add_node("planner", planner_node)
graph.add_node("researcher", researcher_node)
graph.add_node("writer", writer_node)
graph.add_edge("planner", "researcher")
graph.add_conditional_edges(
"researcher",
lambda s: "writer" if s["enough_info"] else "researcher",
)
graph.add_edge("writer", END)
app = graph.compile(checkpointer=PostgresSaver.from_conn_string(DSN))
// OpenAI Agents SDK(TypeScript): handoffを宣言
import { Agent, handoff, run } from "@openai/agents";
const researcher = new Agent({
name: "researcher",
instructions: "Web検索で事実を集める",
tools: [webSearchTool],
});
const writer = new Agent({
name: "writer",
instructions: "集まった事実を日本語レポートに書く",
});
const supervisor = new Agent({
name: "supervisor",
instructions: "タスクに応じて researcher か writer に振る",
handoffs: [handoff(researcher), handoff(writer)],
});
const result = await run(supervisor, userInput);
// Claude Agent SDK(TypeScript): subagentをツールとして登録
import { query } from "@anthropic-ai/claude-agent-sdk";
const result = query({
prompt: userInput,
options: {
// 仕様は公式ドキュメント参照
mcpServers: {
memory: { command: "mcp-memory-server" },
search: { command: "mcp-web-search" },
},
agents: {
researcher: { description: "Web検索して事実を集める" },
writer: { description: "日本語レポート化" },
},
},
});
for await (const msg of result) {
console.log(msg);
}
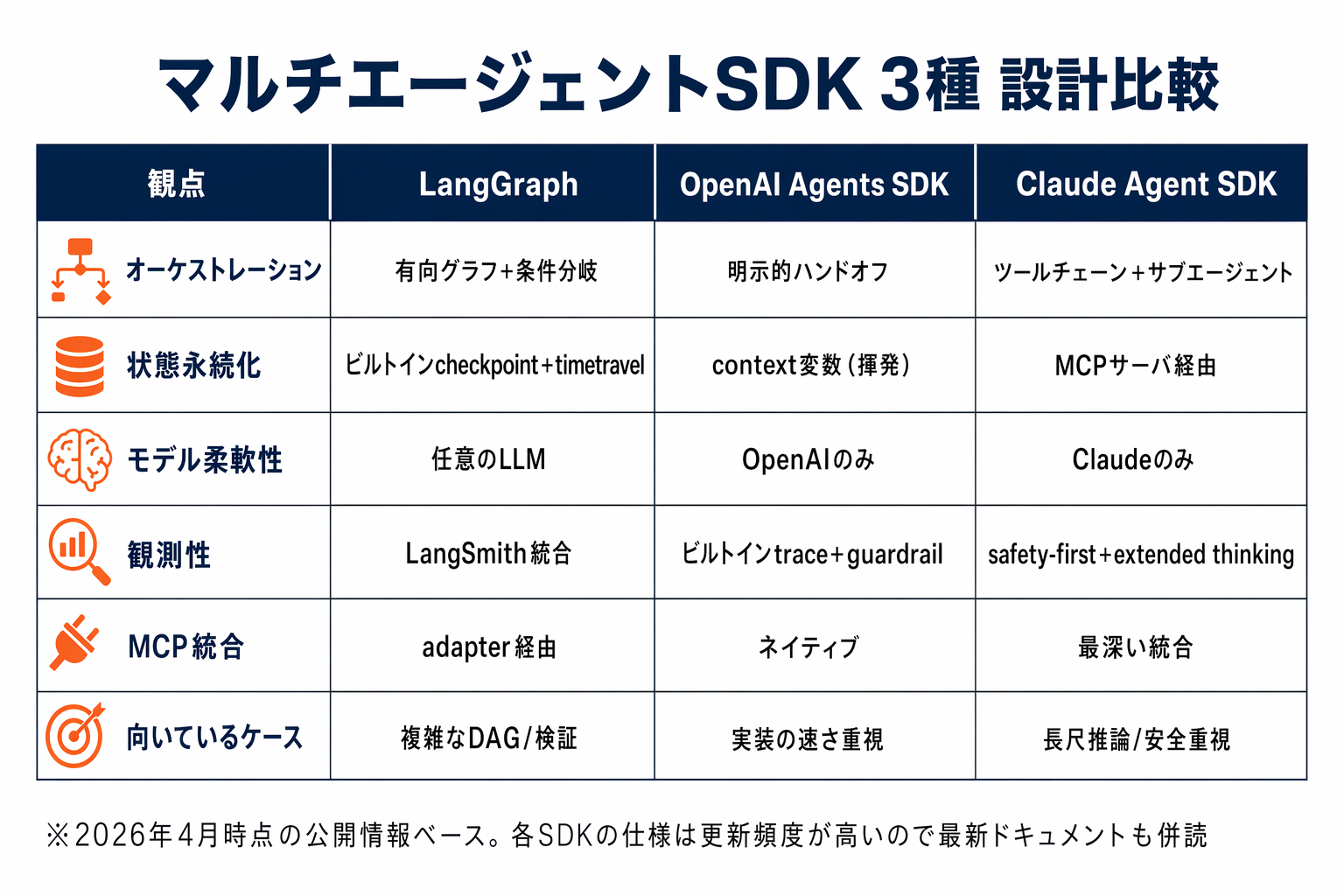
観点3: モデル柔軟性
「どのモデルを使えるか」はロックイン度に直結する。3SDKの方針ははっきり分かれる。
| SDK | 対応モデル | 切り替え容易性 |
|---|---|---|
| LangGraph | LangChainのChatModel実装すべて(Claude / GPT / Gemini / local LLM等) | 高 |
| OpenAI Agents SDK | OpenAIモデル(gpt-5.x / o系)のみ | 低 |
| Claude Agent SDK | Claudeモデルのみ | 低 |
「プランナーはo系の推論モデル、ライターはClaude、要約はローカルLLMに回してコスト削減」といった混成アーキテクチャを組みたいなら、事実上LangGraphの一択になる。逆に、単一モデル前提で最新機能(extended thinking、computer use、structured output 2.0 等)をフルに使いたいなら、ベンダ純正SDKのほうが最初から最適化されている。モデルごとの強み・プロンプト設計の差分は推論モデル時代のプロンプト設計で整理しているため、モデル選定とSDK選定は並行で検討するとよい。
観点4: MCP統合の深さ
Model Context Protocol(MCP)は2024年にAnthropicが発表した「ツール・リソース共通プロトコル」で、2026年時点ではOpenAIもAnthropicも公式対応に踏み切っている。ただし、統合の深さにはばらつきがある。MCPサーバの実装詳細(stdio / Streamable HTTP のトランスポート選択やセキュリティ境界)はMCPハンズオンで扱っているので、SDK選定と合わせて読むと設計判断が立体的になる。
- Claude Agent SDK:MCPはファーストクラスメンバー。ツールも状態(Resources)もMCPサーバ経由が前提の設計で、SDK自体がMCPハブに近い働きをする。
- OpenAI Agents SDK:公式ドキュメントにMCP統合セクションがあり、MCPサーバを直接登録できる。ネイティブ対応だが、「SDKの中心」ではなく「連携先の一つ」という位置づけ。
- LangGraph:
langchain-mcp-adapterなどのアダプタ経由で繋ぐ。動くが、どちらかというとLangChain Toolsの上にMCPを載せている格好で、細かいところで噛み合いが粗い。
複数のエージェント/複数のアプリで 同じMCPサーバを共有したい(例:社内のファイル・ナレッジアクセスを1つのmcp-filesサーバで統一)なら、Claude SDKとOpenAI SDKが有利だ。自作MCPサーバ資産を最大活用したいならClaude SDKが頭一つ抜ける。
観点5: 観測性・デバッグ
エージェントは中で何が起きているかブラックボックスになりやすく、可観測性の優劣がそのまま開発スピードに出る。
LangGraph + LangSmith
LangSmith連携が強力で、グラフ上のどのノードをどの順で通ったか、各ノードの入出力、トークン使用量がすべてトレース画面に可視化される。条件分岐の評価結果もステップごとに残る。時系列でstep-throughできるUIはデバッグに効く。
OpenAI Agents SDK のbuilt-in tracing
SDKに組み込まれたtracingが、OpenAI dashboardと連携して会話単位で残る。エージェント間のhandoffもタイムライン上で追える。設定なしで動くのが強み。
Claude Agent SDK の extended thinking ログ
extended thinkingの思考過程を含めたログが取れる。「なぜこのツールを呼んだか」がモデル自身の推論テキストとして残るため、プロンプト改善に直接繋がる。
OpenTelemetry対応は、LangGraph と OpenAI SDKがネイティブに進んでおり、Claude SDKは個別のexporter実装が必要なケースがある。既存の観測基盤(Datadog、Grafana、Honeycomb等)に流し込むならOTel対応の有無は先に確認したい。
観点6: スケール・運用
プロトタイプを本番に載せる段で効いてくるのが、long-runningとエラー処理、そしてコスト計測だ。
- long-running:LangGraphはcheckpointerとdurable executionの組み合わせで、数時間〜数日のワークフローを自然に書ける。OpenAI / Claudeは単発runが基本で、長時間ワークフローは自前でキュー・ワーカー構成を組むことになる。
- エラー・タイムアウト:各SDKともリトライ/タイムアウト設定は備える。ただし「ツール呼び出し失敗時にハンドオフで別エージェントに回す」のようなフォールバックは、OpenAI Agents SDKのhandoffが書きやすい。
- コスト計測:トークン系のusageはどれも取れる。ただし実行時間/ツール呼び出し回数/外部API費用を合算したコスト監視は、LangSmithが一歩先を行く。大規模運用ではここが効く。
コード比較:「リサーチエージェント」の最小実装を3SDKで
同じ仕様「ユーザーの質問を Web検索 → 要約 → 日本語に翻訳」を3SDKで書くと、書き味の違いがはっきり出る。
LangGraph版:グラフで流れを記述
from langgraph.graph import StateGraph, END
from typing import TypedDict
class S(TypedDict):
question: str
search: str
summary: str
translated: str
def search_node(s: S) -> S:
s["search"] = web_search(s["question"])
return s
def summarize_node(s: S) -> S:
s["summary"] = llm_en.invoke(f"Summarize: {s['search']}")
return s
def translate_node(s: S) -> S:
s["translated"] = llm_ja.invoke(f"日本語に訳して: {s['summary']}")
return s
g = StateGraph(S)
g.add_node("search", search_node)
g.add_node("summarize", summarize_node)
g.add_node("translate", translate_node)
g.set_entry_point("search")
g.add_edge("search", "summarize")
g.add_edge("summarize", "translate")
g.add_edge("translate", END)
app = g.compile()
print(app.invoke({"question": "MCPとは?"}))
グラフを見れば処理フローが一目で分かる。ノード追加や条件分岐もエッジを書き換えるだけで、大規模化しても構造が崩れにくい。
OpenAI Agents SDK版:ハンドオフで繋ぐ
import { Agent, handoff, run, tool } from "@openai/agents";
const searchTool = tool({
name: "web_search",
description: "Web検索する",
// 仕様は公式ドキュメント参照
parameters: { query: "string" },
execute: async ({ query }) => webSearch(query),
});
const summarizer = new Agent({
name: "summarizer",
instructions: "英語で簡潔に要約する",
});
const translator = new Agent({
name: "translator",
instructions: "受け取った英語要約を自然な日本語に翻訳する",
});
const researcher = new Agent({
name: "researcher",
instructions:
"web_searchで調べ、summarizerに要約させ、最後にtranslatorに渡す",
tools: [searchTool],
handoffs: [handoff(summarizer), handoff(translator)],
});
console.log(await run(researcher, "MCPとは?"));
各エージェントが独立した人格を持ち、「誰に渡すか」をLLMが判断する。プロンプトでhandoff条件を明示的に書くほど動きが安定する。
Claude Agent SDK版:サブエージェントをツール的に呼ぶ
import { query } from "@anthropic-ai/claude-agent-sdk";
const result = query({
prompt: "MCPとは?を日本語でリサーチレポートにして",
options: {
// 仕様は公式ドキュメント参照
mcpServers: {
search: { command: "mcp-web-search" },
},
agents: {
summarizer: {
description: "英語要約専任",
prompt: "与えられた検索結果を3段落で要約する",
},
translator: {
description: "英→日翻訳専任",
prompt: "自然な日本語ビジネス文体に訳す",
},
},
allowedTools: ["mcp__search__web_search"],
},
});
for await (const msg of result) {
if (msg.type === "result") console.log(msg.result);
}
親Claudeが1つの会話コンテキストを保ったまま、必要に応じてサブエージェントに分岐させる。MCPサーバをそのまま繋げるので、ツール層の設計が素直になる。
選定の実務フロー
ここまでの観点を、実装前の選定フローに落とし込むと次のような順番で絞り込める。
- モデルに制約はあるか? 社内規程で「OpenAIしか通らない」「Claudeしか使えない」がある場合は、対応する純正SDKで確定。
- 状態永続化とtime-travelが必須か? YESならLangGraph。人手レビューを挟むworkflowや、長時間走るジョブが多いならここで決まる。
- MCPエコシステムを深く使いたいか? 自作MCPサーバ資産が多い、社内で共通化したい、ならClaude Agent SDKが最深。OpenAI Agents SDKも十分対応する。
- シンプルさと立ち上がりの速さを優先するか? YESならOpenAI Agents SDKが最短。ハンドオフの概念だけで書き始められる。NOならLangGraphで表現力を取りに行く。
- マルチモデル(コスト最適化)したいか? YESならLangGraph一択。
この順で上から落としていくと、たいてい2つに絞られる。そこからチームの言語(Python中心かTypeScript中心か)と既存観測基盤との相性で決めれば、大きく外さない。
落とし穴・アンチパターン
3SDKに共通してやりがちな失敗パターンを挙げておく。
- 「とりあえずマルチエージェント」病:1エージェント+Toolsで済む問題を、わざわざSupervisor + Workerに分けてコンテキスト断絶を招くケース。まずシングルエージェントで書き、明確に役割分離が必要になってから分けるのが定石。
- handoff頻発:OpenAI Agents SDKで小さなエージェントを量産し、会話が何度もhandoffされる設計は、会話履歴を爆発させコストを押し上げる。粒度は「独立した責務を持つか」で判断する。
- グラフが柔軟すぎてデバッグ困難:LangGraphで条件分岐を増やしすぎると、実際にどの経路を通ったか追うのに時間が取られる。早い段階で経路別のテストケースを書き、LangSmithでの再現テスト運用に乗せる。
- MCPサーバの粒度設計:Claude Agent SDKで全ツールを1つのMCPサーバに詰めると、権限管理もリリースサイクルも肥大化する。リソース単位で分割する。
- 状態をプロンプトに詰め込む:コンテキストを長大なシステムプロンプトに持たせるのは、観測性もコストも悪化させる。外部Store(LangGraphならstate、ClaudeならMCP Resources)に出す判断を早めに行う。
まとめ
- LangGraphはグラフ×checkpointer×マルチモデルで、状態と表現力を最優先したいときの本命。
- OpenAI Agents SDKはhandoff中心のシンプルなモデルで、OpenAIモデル前提なら立ち上げが最速。
- Claude Agent SDKはMCPファーストとextended thinkingが強みで、安全性と推論深度を重視する領域にフィットする。
- 単一勝者はなく、モデル制約・永続化要件・MCP資産・観測基盤の4点で落としていけば、選択はほぼ機械的に決まる。
(SDKの仕様は2026年4月時点の情報です。各SDKは頻繁にアップデートされるため、採用時には最新の公式ドキュメントを併読してください)