2026年に入り、主要ベンダー各社の「推論モデル(reasoning model)」が一通り出揃いました。Anthropic の Claude Opus 4.6 Thinking、OpenAI の GPT-5.4、Google の Gemini 3.1 Pro、xAI の Grok 4。ベンチマークはどれも僅差で、"1位"は計測項目ごとに入れ替わります。本記事では、LLM API を実務で叩いているエンジニア・PM 向けに、推論モデルの内部挙動・各モデルの強み・プロンプト設計の原則・コスト構造・選定フローを、2026年4月時点の情報で整理します。
そもそも推論モデル(reasoning model)とは何が違うのか
推論モデルは、出力を生成する前に「内部で思考を回す」モデルを指します。従来モデルが入力から直接トークン列を生成するのに対し、推論モデルは thinking tokens(または reasoning tokens)と呼ばれる中間トークン列をまず生成し、それをもとに最終的な応答を組み立てます。
思考トークンの内部
思考トークン自体は多くの場合エンドユーザーには返されず(Anthropic の Claude では要約が返る、OpenAI の o系/GPT-5 系は原則隠される)、請求上はカウントされます。モデル側は「この問題を解くために、どの前提を並べ、どの分岐を検討すべきか」を内部で吐き出してから回答に進むため、単純な1回の forward pass では到達しにくい結論に到達できる、というのが基本的な考え方です。
単発推論との違い
従来モデルで Chain-of-Thought(CoT)を外部プロンプトとして書き下す方法と、推論モデルの内部推論は、挙動こそ似ていますが性格が異なります。外部 CoT は「出力トークンの一部として」思考が流れるのに対し、推論モデルの思考は 出力品質のための前処理として消費される。結果として、最終応答は短く整った形でも、その裏で数千〜数万トークンの思考が走っている、ということがあり得ます。
レイテンシとコストの構造的な上昇
この構造上、推論モデルは原理的に遅く、原理的に高いです。1リクエストあたりのレイテンシは数秒〜十数秒のオーダーに伸びることが普通で、ユーザーが入力してから応答が返るまでの体感は、従来の会話モデルとは明確に異なります。「推論モデルを使えば何でも良くなる」というより、時間と金を使って精度を買う、という理解が正しい設計視点です。
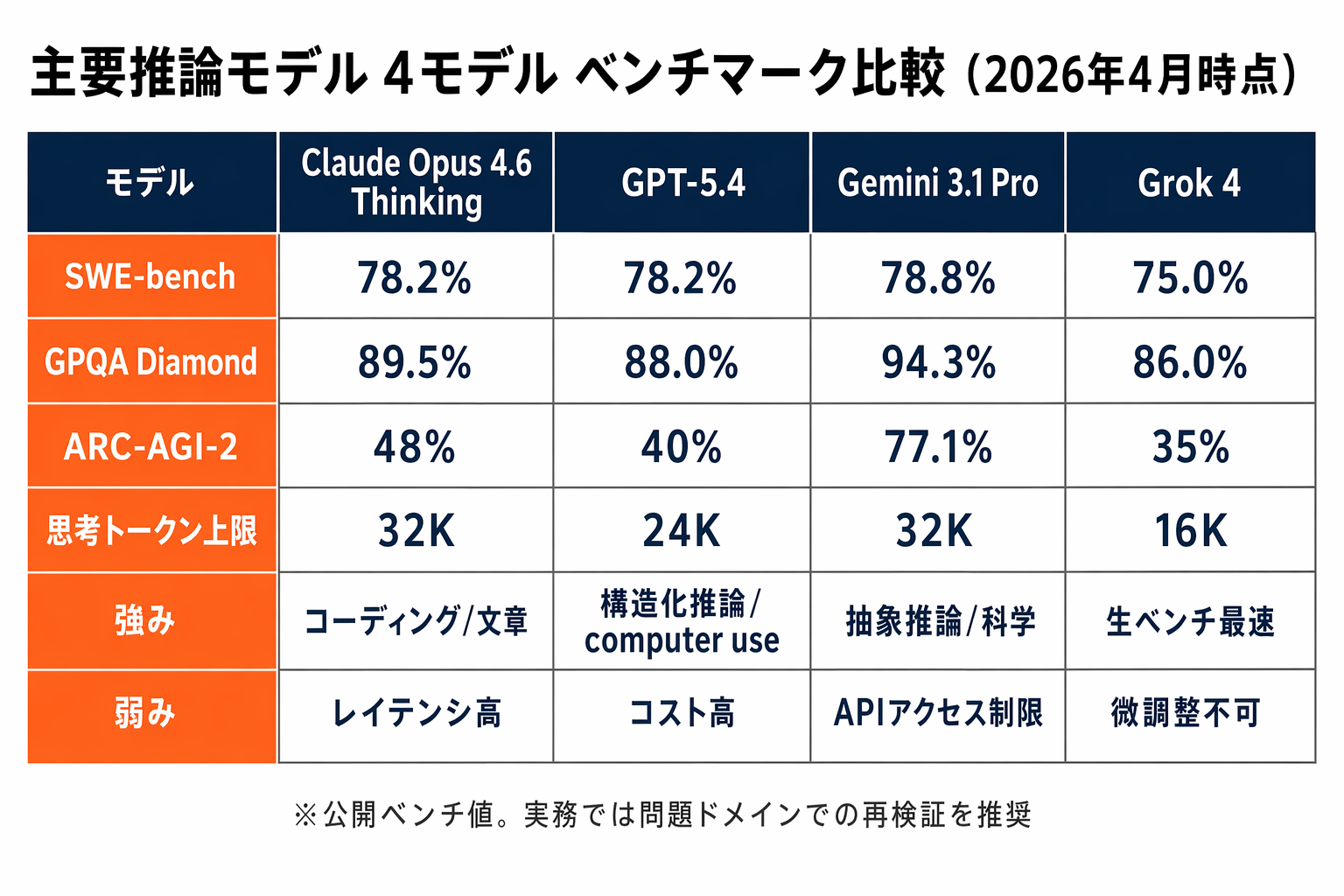
2026年4月時点の4モデル:強みの違い
以下、4モデルの特徴を公開ベンチと一次情報ベースでまとめます。ベンチマーク値は2026年3〜4月時点の各社公表値を用いています。
Claude Opus 4.6 Thinking(Anthropic)
- Thinking 予算上限: 最大 32K thinking tokens
- SWE-bench Verified: 78.2%
- GPQA Diamond: 89.5%
- 強み: コーディング、長文の構造維持、日本語を含むニュアンスのある文章生成
コードリファクタや長いレビュー、含意の多い自然言語の書き換えで安定して高評価を得やすい設計です。Anthropic SDK の thinking パラメータで予算を明示できるため、「どこまで考えさせるか」をアプリ側でコントロールしやすい点が実装上の扱いやすさに繋がっています。
GPT-5.4(OpenAI)
- SWE-bench Verified: 78.2%
- GPQA: 88%
- 強み: 構造化推論、関数呼び出し/ツール使用の頑健さ、computer use 系タスク
複数ツールを跨ぐエージェント的なワークフローや、JSON Schema を厳密に守らせたい構造化出力タスクで強みが出やすい傾向があります。reasoning_effort の概念で思考量を調整する API 設計が広く浸透しつつあり、開発者から見るとチューニング粒度がわかりやすいのが利点です。
Gemini 3.1 Pro(Google)
- SWE-bench Verified: 78.8%
- GPQA Diamond: 94.3%
- ARC-AGI-2: 77.1%
- 強み: 抽象推論、科学・数理系、マルチモーダル入力
GPQA Diamond と ARC-AGI-2 のスコアは 2026年4月時点で突出しており、数学・物理・化学・生物の専門問題や、パターン認識を伴う抽象推論課題での優位が目立ちます。長大なコンテキスト処理と合わせ、論文読解・R&D 支援・データ分析系で採用しやすいモデルです。
Grok 4(xAI)
- SWE-bench Verified: 75%
- 強み: 生のベンチマーク上での応答速度
純粋な精度では他3モデルに一歩譲りますが、思考時間が比較的短く、コスト/レイテンシ/精度のトレードオフの別の点を提供するモデルとして選択肢に入ります。
ベンチマークの読み方
4モデルのスコアを並べて眺めると、「どれを選んでも大差ない」ように見えます。実務ではむしろ、どのベンチマークで何を測っているのかを理解したうえで、自分のユースケースに近いベンチを参考にするのが正解です。
SWE-bench Verified
GitHub の実 issue に対してパッチを生成し、既存テストが通るかを評価するコーディング系ベンチ。「コードが実際に動くか」を見ているので、コード生成・自動修正の用途では最も参照価値が高いスコアです。
GPQA Diamond
物理・化学・生物の大学院レベルの問題。Google 検索等では解きづらいように設計されていて、モデルの「本当の推論力」に近いものを測っているとされます。数理・科学・論理問題の性能指標として見られます。
ARC-AGI-2
ARC 系の抽象推論タスクで、「未知のパターンを数例から一般化する」力を測ります。知識量ではなく一般化能力が問われるため、データが薄い領域での推論のロバストさを見るのに向いています。
ベンチが示さないもの
一方で、以下はベンチ数値にほとんど表れません。実務採用の判断では、むしろこちらの比重が高くなります。
- 出力文章の体感品質(誤用のしなさ、読みやすさ、トーン)
- ツール呼び出しの頑健さ(JSON 形式崩れ、同一ツールの繰り返し呼び出しの傾向)
- 日本語の自然さ、敬語・業界用語の扱い
- 長時間セッションでの一貫性
- エラー時のフェイルセーフ挙動
推論モデルに対するプロンプト設計の原則
推論モデルは、従来モデル向けのプロンプトテクニックがそのままでは効かない、もしくは逆効果になることがあります。以下は2026年4月時点で各社が公式ドキュメントで推奨している方向と、実装現場で落ち着いてきた原則の交差点です。
原則1:Chain-of-Thought を明示しない
「ステップバイステップで考えて」「まず推論してから答えて」といった CoT 系の指示は、推論モデルでは不要であり、場合によってはノイズになります。モデルは内部ですでに思考を回しており、外部 CoT を重ねると、思考フェーズが出力側に漏れたり、二重の整形で冗長化したりします。
原則2:制約とゴールを分離する
推論モデルはプロンプトの構造に素直です。ツール呼び出しと絡めて使う場合は、MCPのような標準プロトコルで外部機能を切り出しておくと、プロンプト側のセクション分けも綺麗になります(実装例はMCPハンズオン参照)。以下のような明確な分離が効きます。
- 役割: モデルが誰として振る舞うか
- 入力: 与えるデータ/コンテキスト
- 期待される出力: 形式・長さ・粒度
- 禁止事項: やってはいけないこと
XML タグや見出しで明示的にセクション分けするのは、Anthropic・OpenAI・Google いずれのモデルでも有効です。
原則3:JSON スキーマ要求はトップに置く
構造化出力を求める場合、「必ずこの形式で返す」という指示はプロンプトの先頭に置くほうが安定します。入力データやコンテキストを先に並べてから最後に形式指定を書くと、思考過程が長くなった際に形式指定が相対的に薄まり、崩れやすくなります。
原則4:self-check を短く添える
「出力前に次の観点でセルフチェック:1) 事実関係、2) 形式、3) 矛盾」のような短い検算指示は、推論モデルでも有効です。ただし検算観点を長く書きすぎると、内部思考の向きが検算側に偏り、本体の推論が薄くなることがあります。3〜5項目の箇条書き程度に留めるのが目安です。
原則5:few-shot は最小限
従来モデルでは十数例の few-shot が効く局面がありましたが、推論モデルでは逆に冗長な例示によって崩れることが観測されています。2〜3例で足りるなら3例まで、それ以上は "スキーマ説明 + 1例" で十分なことが多いです。
原則6:思考予算を適切に切る
Anthropic の budget_tokens、OpenAI の reasoning_effort(low/medium/high)、Gemini の thinking 有効化フラグなど、どのベンダーも「どれだけ考えさせるか」を指定できます。簡単なタスクに最大予算を当てると、無駄なコストとレイテンシだけが増えます。難易度に応じて段階的に上げるのが基本です。
コストとレイテンシの実務見積もり
推論モデルの請求は大きく 3系統で積み上がります。
- 入力トークン: プロンプト・システム指示・コンテキスト
- 出力トークン: 最終応答
- 思考トークン: 内部推論で消費された分(ユーザーには大半が返らないが課金対象)
難問に対して thinking を最大予算で走らせると、思考トークンだけで入出力合算の数倍を占めることも珍しくありません。「API 料金表の見かけの単価より、実効コストが3〜10倍になる可能性がある」と見積もっておくと大きく外しません。
レイテンシの目安
1秒以内の応答を期待する UX(チャットの最初の1レス、入力補完など)には、推論モデルを前面に置かないのが定石です。以下の切り分けが実務的です。
- 会話応答・軽い要約・分類: 従来モデル(Claude Sonnet、GPT-5 mini、Gemini Flash 系)
- 長考タスク(レビュー、設計、複雑推論、エージェントのボトルネック): 推論モデル
バッチ・非同期前提で組む
推論モデルの呼び出しは、同期 API で待つよりも、ジョブキュー+非同期処理に乗せる設計が自然です。応答時間が10秒を超える可能性がある処理を HTTP リクエストの中で待たせると、タイムアウトや UX 毀損のリスクが上がります。バッチ API を提供しているベンダーは、思考コストのディスカウントが効くことも多いので、非同期で良い用途はまずバッチを検討します。マルチエージェント構成で推論モデルをコア推論に置き、要約・整形は軽量モデルにオフロードする設計はマルチエージェントSDKの設計比較で扱っています。
ユースケース別の使い分け
2026年4月時点のベンチと実運用の所感を踏まえた、ユースケース別の推奨です。数値差は僅差のため、必ず自社ドメインでの小規模 A/B を推奨します。
| ユースケース | 推奨1位 | 推奨2位 | 理由 |
|---|---|---|---|
| コード生成・リファクタ | Claude Opus 4.6 Thinking | GPT-5.4 | SWE-bench 同率だが、長文の構造維持とリファクタの破壊少なさで Claude が選ばれやすい |
| 数学・科学推論 | Gemini 3.1 Pro | Claude Opus 4.6 Thinking | GPQA Diamond / ARC-AGI-2 の優位が明確 |
| エージェント実装(ツール呼び出し) | GPT-5.4 | Claude Opus 4.6 Thinking | ツール呼び出しの頑健さ、computer use 系の実績 |
| 法務・契約書レビュー | Claude Opus 4.6 Thinking | Gemini 3.1 Pro | 長文での前提保持とニュアンス処理 |
| データ分析・探索 | Gemini 3.1 Pro | GPT-5.4 | 抽象推論とマルチモーダル、長大コンテキスト |
| 日本語編集・文章生成 | Claude Opus 4.6 Thinking | Gemini 3.1 Pro | 敬語・含意・トーンの扱いが安定する傾向 |
実装Tips(最小コード例)
以下は2026年4月時点のSDK挙動を前提とした最小呼び出し例です。SDKのAPI名・パラメータ名は版によって変わるため、本番採用前には最新のSDKドキュメントを参照してください。
Anthropic SDK:extended thinking の有効化
import Anthropic from "@anthropic-ai/sdk";
const client = new Anthropic();
const res = await client.messages.create({
model: "claude-opus-4-6-thinking",
max_tokens: 4096,
thinking: {
type: "enabled",
budget_tokens: 8000,
},
messages: [
{ role: "user", content: "このSQLクエリのパフォーマンス問題を特定して修正案を3つ出してください。\n\n..." },
],
});budget_tokens で思考の上限を切ります。難易度が低い場面では小さく、エージェントのコア推論では大きく、と使い分けるのが基本です。
OpenAI SDK:reasoning_effort の指定
import OpenAI from "openai";
const client = new OpenAI();
const res = await client.responses.create({
model: "gpt-5.4",
input: "次の設計案のトレードオフを、セキュリティ/運用/コストの観点で評価してください。\n\n...",
reasoning: { effort: "high" },
});effort は low/medium/high のような粒度で指定する設計が広がっています。仕様は最新のSDKドキュメントを参照してください。
Gemini SDK:thinking の有効化
import { GoogleGenAI } from "@google/genai";
const ai = new GoogleGenAI({ apiKey: process.env.GOOGLE_API_KEY });
const res = await ai.models.generateContent({
model: "gemini-3.1-pro",
contents: "このCSVのカラム間の相関を仮説ベースで3つ挙げ、検証手順を示してください。\n\n...",
config: {
thinkingConfig: { thinkingBudget: 8000 },
},
});パラメータ名は SDK 版によって thinkingBudget / thinking 等に揺れがあります。正確な指定名は最新のSDKドキュメントを参照してください。
JSON 強制の与え方
// OpenAI: Structured Outputs
const res = await client.responses.create({
model: "gpt-5.4",
input: userInput,
reasoning: { effort: "medium" },
text: {
format: {
type: "json_schema",
name: "review_result",
schema: {
type: "object",
properties: {
verdict: { type: "string", enum: ["approve", "request_changes"] },
reasons: { type: "array", items: { type: "string" } },
},
required: ["verdict", "reasons"],
additionalProperties: false,
},
strict: true,
},
},
});Anthropic では tool use を使った JSON 強制、Gemini では responseMimeType: "application/json" と responseSchema の組み合わせが使われます。いずれも仕様は最新のSDKドキュメントを参照してください。
選定の実務フロー
新しいユースケースに推論モデルを入れるかどうかの判断は、次の順序で進めるとコストが膨らみにくいです。
1. まず従来モデルで解けるか試す
Claude Sonnet 系、GPT-5 mini、Gemini Flash 系で解けるなら、それが最適解であることが多いです。推論モデルは「従来モデルで精度が足りないことが確認できてから」考えます。
2. ベンチより自分のドメインでA/B
SWE-bench も GPQA も汎用指標に過ぎません。自社のユースケースから50〜100件のサンプルを切り出し、同一プロンプトで Claude / GPT-5 / Gemini を並列で走らせ、自分たちが信じる評価軸(正確さ、形式遵守、コスト、P95 レイテンシ)でスコアリングするのが、最短の意思決定パスです。
3. モデル変更の退行テスト
モデルを差し替えた瞬間、既存プロンプトの挙動が微妙に変わります。特に「JSONの末尾にコメントが混じる」「禁止事項の表現を無視する」「過剰に謙遜する」といった差分が出やすいポイントです。モデル変更時は、少なくとも主要プロンプトに対する回帰スイート(期待出力との一致率、形式エラー率、ツール呼び出し成功率)を走らせるのが安全側です。
まとめ
- 2026年4月時点の4モデル(Claude Opus 4.6 Thinking / GPT-5.4 / Gemini 3.1 Pro / Grok 4)は総合で僅差。ユースケースで勝者が変わる。
- 推論モデルでは CoT 指示は不要。制約とゴールの分離、JSON 要求の先頭配置、短い self-check が効く。
- コストは入力・出力・思考の3系統。レイテンシは数秒〜十数秒前提でバッチ/非同期に組む。
- ベンチは地図、A/B は現地調査。自分のドメインで小規模 A/B を回してから採用する。
(ベンチマーク値は2026年3〜4月時点の各社公開データに基づきます。モデルは頻繁に更新されるため、本番採用前には自社ドメインでの検証を推奨します)