
LLMエンジニアの学習は、情報量が多いわりに「どの順序で何を身につけるか」を示したロードマップが少ない。論文を追いかけるだけでも、プロンプトだけ書けても、実務で通用するエンジニアにはならない。本記事では、基礎理解・アプリ実装・運用評価の3層をバランスよく積み上げる6ヶ月のロードマップを、月次の到達点・アウトプット・評価手法とセットで提示する。既にWebアプリやバックエンドの開発経験があるITエンジニアを主な想定読者として、独学・社内プロジェクト・転職準備のいずれにも流用できる形で整理した。
この記事でわかること
- LLMエンジニアに必要な3層のスキル(基礎理解/アプリ実装/運用・評価)の分解
- 6ヶ月で実務レベルに到達するための月次ロードマップ
- プロンプト/RAG/Agent/運用評価それぞれの学習順序と到達点
- 公式ドキュメント中心の推奨リソースとハンズオン教材
- 論文偏重・汎用ベンチ偏重など、陥りやすい失敗パターン
- 学習成果をポートフォリオ/GitHub/OSS貢献としてキャリアに換算する方法
- FAQ(数学・言語選択・フレームワーク・論文の追い方・転職時期)
LLMエンジニアに求められる3層のスキル
LLMエンジニアという肩書きは業界でまだ揺らいでいるが、実務で求められる能力は概ね次の3層に分解できる。どれか1層に偏ると、どこかで必ず限界が来る。
- 基礎理解:Transformer、トークン、埋め込み、コンテキスト窓、推論コスト、推論モデルといった「モデルがどう動くか」を言語化できる層。
- アプリ実装:プロンプト設計、構造化出力、RAG、Tool Use(function calling)、Agent、MCP連携といった「アプリとして組み立てる」層。
- 運用・評価:LLMOps、評価セット設計、幻覚検出、コスト最適化、セキュリティ、オンライン評価といった「本番で壊さず回す」層。
研究寄りのエンジニアはさらにファインチューニングや蒸留を含む4層目を持つが、多くの現場では外部APIを前提にした3層構成で十分に差別化できる。特に3層目の「運用・評価」は、プロンプトが書けるだけの人材との差が出やすい領域であり、キャリアの後半に向けて重点的に積み上げる価値が高い。
一般的なWebエンジニアからの移行ルートとしては、AIエンジニアのキャリアパスも併せて確認しておくと、技術選択と役割の輪郭がつかみやすい。
6ヶ月学習ロードマップの全体像
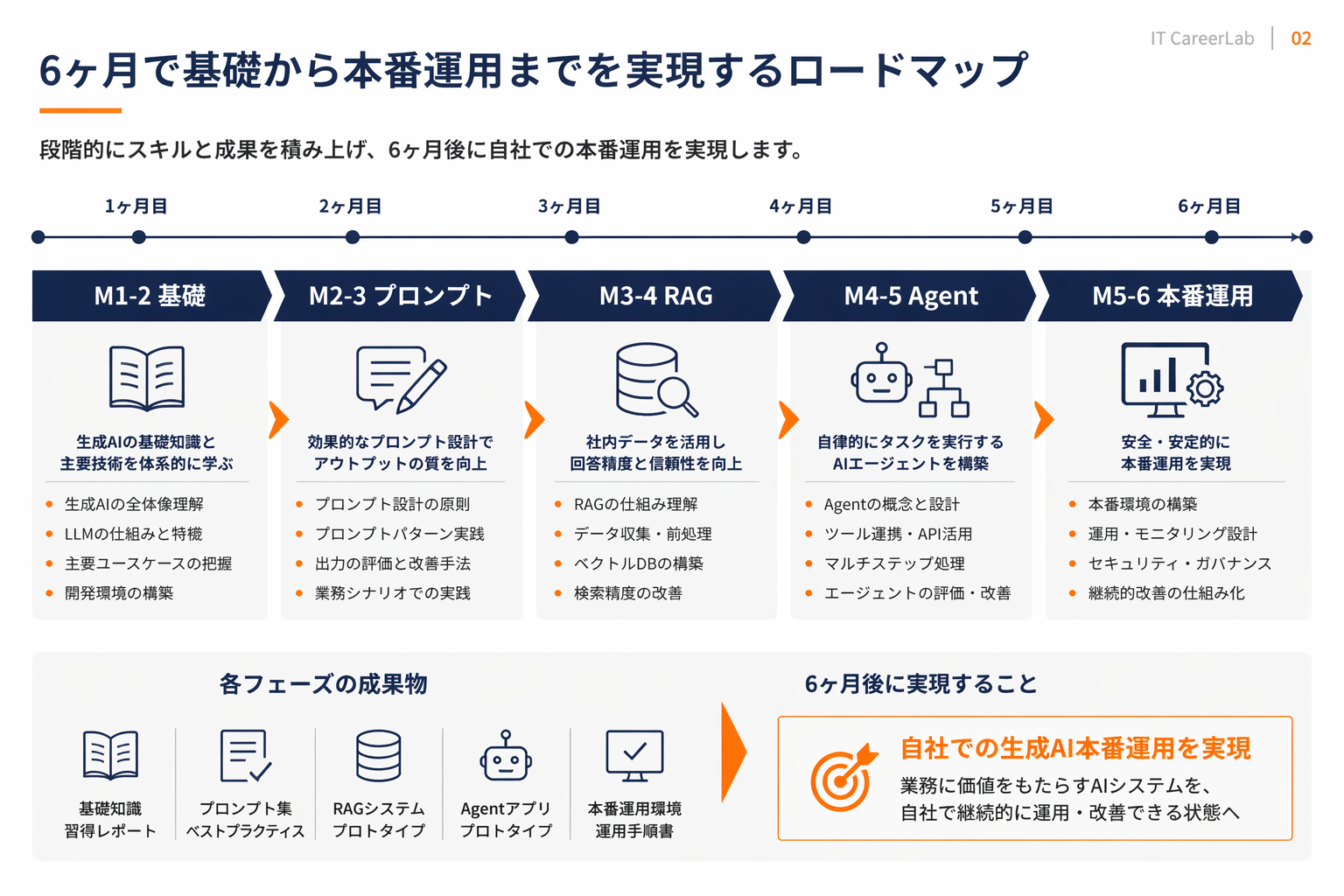
以下の表は、平日1〜2時間+週末4〜6時間の学習時間を想定した6ヶ月ロードマップだ。個人のバックグラウンドにより伸縮するため、期間よりも「アウトプット」の完成度を基準に進むことをお勧めする。
| 月 | 学習テーマ | アウトプット | 到達点の目安 |
|---|---|---|---|
| 1〜2 | LLMの基礎理解(Transformer/トークン/埋め込み/推論コスト/コンテキスト窓/推論モデル) | 公式APIを直接叩くCLIツール、トークン計算の自作スクリプト | モデルの挙動を概念レベルで言語化できる |
| 2〜3 | プロンプトエンジニアリング実務(Few-shot/Chain-of-Thought/構造化出力/Self-consistency/評価セット) | 業務課題1つを題材にしたプロンプト改善レポート(評価セット付き) | プロンプト変更の効果を数値で比較できる |
| 3〜4 | RAGアーキテクチャ(チャンキング/ベクトル検索/ハイブリッド検索/引用生成/評価) | 社内ドキュメントまたは公開データセットを用いたRAGアプリのデモ | Retrieval品質とGeneration品質を分離して評価できる |
| 4〜5 | Agent/Tool Use実装(function calling/MCP/マルチエージェント連携/エラー復帰) | ツール3つ以上を束ねるAgentと、MCPサーバーの実装 | 失敗時のリトライ/フォールバック戦略を設計できる |
| 5〜6 | 本番運用・評価(LLMOps/コスト最適化/幻覚検出/オンライン評価/セキュリティ) | 監視ダッシュボード付きのサービス化デモ、脅威モデル文書 | 本番リリース可能な品質・コスト・安全性の3観点で説明できる |
このロードマップは、システム設計の学習ロードマップとクラウド資格の優先度マップで示したのと同じく「書籍/公式ドキュメント/手を動かすアウトプット」の3本柱で構成している。どれか1本だけで完走するのは難しい。
月1〜2:LLMの基礎理解
最初の2ヶ月は、モデルの内部挙動を言語化できる状態を目指す。数式の導出は不要だが、以下のキーワードは自分の言葉で説明できるところまで持ち上げたい。
- Transformer:自己注意機構(Self-Attention)を核とする系列変換モデル。なぜRNNから置き換わったのかをトレードオフで語れるように。
- トークン:入力テキストがBPEやTiktoken等で分割される単位。日本語は英語より1文字あたりのトークン数が多く、コスト試算に影響する。
- 埋め込み(Embedding):文字列を固定長ベクトルへ変換する操作。RAGや検索の土台で、距離尺度(コサイン類似度)とセットで理解する。
- コンテキスト窓:モデルが一度に受け取れるトークン数。長いほど良いわけではなく、コストと注意の希薄化を考慮する。
- 推論コスト:入力/出力トークン単価の非対称性、キャッシュ機構、バッチ処理の有無が総コストを決める。
- 推論モデル(Reasoning Models):思考プロセスを内部で展開するモデル群。推論トークンがコストと応答時間に効くため、通常モデルと使い分ける。推論モデル固有のプロンプト設計は推論モデルのプロンプト設計で深掘りしている。
この段階のアウトプットとして、OpenAIまたはAnthropicの公式SDKで「APIを直接叩く最小CLI」を作ることをお勧めする。ライブラリの抽象化に頼らず、HTTPリクエスト→レスポンスの構造を自分で組むことで、後のプロンプト設計やAgent実装で何が起きているかの解像度が大きく変わる。
月2〜3:プロンプトエンジニアリング実務
基礎理解が固まったら、プロンプトを「書ける」から「評価できる」状態に引き上げる。この段階で重要なのは、プロンプトを文芸作品のように磨くことではなく、評価セットを先に作る習慣を身につけることだ。
- Few-shot:例示を本文に含めてタスクを伝える基本技法。例示の選び方・順序・件数で出力は大きく変わる。
- Chain-of-Thought(CoT):思考過程を明示させる手法。推論モデルの登場で使いどころは変化しており、通常モデルと推論モデルで設計を切り替える必要がある。
- 構造化出力:JSON Schema や tool call によるスキーマ保証。自由文で返すよりパース安定性が段違いで、本番アプリの大半はここに寄せる。
- Self-consistency:複数サンプル生成から多数決を取る手法。コストと引き換えに精度を安定させる。
- 評価セット:入力例と期待出力(または期待する性質)を紐付けたデータセット。プロンプト変更の効果測定に必須。
評価セットは、最初は10件程度の手動キュレーションで十分だ。大切なのは、プロンプトを変えるたびに同じセットで数値を出し、「なぜ上がった/下がったか」を言語化する癖を作ること。この癖がつくと、後のRAGやAgent開発でも同じ評価フレームを転用できるようになる。
月3〜4:RAGアーキテクチャ
RAG(Retrieval-Augmented Generation)は、外部知識を検索してモデルに与える構成で、LLMアプリで最頻出のパターンだ。学習のコツは「Retrieval品質」と「Generation品質」を分けて評価することにある。両者を混ぜたまま最適化すると、どこに問題があるかが見えなくなる。
- チャンキング:元文書を検索単位に分割する設計。固定長/意味単位/階層構造のどれを選ぶかで下流の検索精度が決まる。
- ベクトル検索:埋め込みモデルとベクトルDBの組み合わせ。pgvector/Qdrant/Pineconeなど選択肢は多いが、最初はpgvectorのような既存DB拡張で十分。
- ハイブリッド検索:BM25などの語彙検索とベクトル検索を組み合わせる手法。固有名詞や略語がキーになる業務ドメインでは、ベクトル単独よりハイブリッドが安定することが多い。
- リランキング:1次検索結果を別モデルで再順位付けする層。上位20件→5件に絞る用途に効く。
- 引用生成:出力に根拠ドキュメントを紐付ける設計。幻覚対策と信頼性の両面で本番RAGには必須。
- 評価:Retrievalは Recall@k/MRR、Generationは faithfulness(根拠忠実度)/answer relevance で分けて測る。
学習アウトプットとしては、公開データセット(Wikipediaダンプ、技術書のマークダウン、社内規程のダミーなど)を題材にRAGアプリを1つ完走させるのが良い。評価セットを事前に作り、チャンクサイズやリランキングの有無でどう数値が動くかを観察すると、パラメータ調整の直感が身につく。
月4〜5:Agent/Tool Use実装
Agentは「LLMがツールを呼び出して目的達成まで自走する」設計で、2025〜2026年にかけて急速に実装ノウハウが整備された領域だ。RAGが「情報を取ってくる」パターンであるのに対し、Agentは「行動する」パターンであり、失敗時の復帰設計が難度の中心になる。
- function calling:LLMがJSON形式で関数呼び出しを生成し、アプリ側で実行して結果を戻す基本構造。各社SDKで標準化されている。
- MCP(Model Context Protocol):ツール/リソース/プロンプトを標準プロトコルで公開する仕組み。実装詳細はMCPハンズオン記事にまとめている。
- マルチエージェント連携:役割分担した複数エージェントを協調させる設計。オーケストレータ型、ピア型、階層型など複数のパターンがあり、選定基準はマルチエージェントSDK比較で整理している。
- エラー復帰:ツール呼び出しの失敗時にどう立て直すか。リトライ/フォールバック/部分成功のハンドリングを設計に組み込む。
- ループ制御:無限ループ/コスト暴走を防ぐための最大ステップ数/最大トークン数の上限設計。
この段階では、ツール3つ以上(たとえば「Web検索」「計算」「社内DB検索」)を束ねるAgentを自作し、失敗パターンを意図的に再現して復帰挙動を検証すると理解が深まる。MCPサーバーを1本書いてClaude CodeやCursorに接続するところまで行くと、ツール公開側の視点まで得られる。
月5〜6:本番運用・評価
最後の2ヶ月は、プロダクトとして成立させるための運用観点を積む。LLMアプリは「動いた」と「本番で壊れない」の距離が通常のWebアプリより大きく、ここを埋められる人材が市場では希少だ。
- LLMOps:プロンプト・モデル・評価セットをバージョン管理し、変更影響をCIで検知する運用。プロンプトのGitOps的な管理が中心課題になる。
- コスト最適化:プロンプトキャッシュ、バッチAPI、モデルのルーティング(簡単な質問は軽量モデル/難しい質問は推論モデル)を組み合わせる。
- 幻覚検出:出力と根拠ドキュメントの整合性を別モデルで検証する仕組み、または構造化出力と型検証を組み合わせる設計。
- オンライン評価:A/Bテスト、影評価(Shadow evaluation)、ユーザーフィードバック(thumb up/down)のシグナルを評価セットに戻すループ。
- セキュリティ:プロンプトインジェクション、データ漏洩、SSRF、権限昇格の4点を最低ラインで固める。Agentが外部APIを叩く場合はSSRFと認可スコープに特に注意する。
以下は、LLMアプリで使われる代表的な評価手法を比較した表だ。どれか1つに頼らず、オフラインとオンラインの評価を組み合わせるのが実務の基本になる。
| 評価手法 | 得意領域 | 限界 | 使いどころ |
|---|---|---|---|
| ユニットテスト(ルールベース) | 出力フォーマット、禁止語、必須要素の検査 | 意味的な正しさは測れない | CIで回す最低ライン、構造化出力の検証 |
| LLM-as-a-Judge | 意味的な一致度、複数観点の採点 | ジャッジモデル自体のバイアスとコスト | 評価セットが大きい場合のオフライン評価 |
| 人手評価 | 微妙なニュアンス、ユースケース特有の判断 | スケーラビリティとコスト | リリース前のゴールデンセット、Judge の校正 |
| オンラインA/B | 実ユーザーの選好、ビジネスKPIとの相関 | サンプルサイズとセットアップコスト | 本番トラフィックに対するモデル/プロンプト比較 |
| フィードバックシグナル | ユーザーの主観的満足度 | サイレントマジョリティの挙動が抜け落ちる | 評価セットへのフィードバックループ形成 |
本番運用の知見は、書籍よりもOpenAI/Anthropic/Google DeepMindの公式エンジニアリングブログや、各社SDKの実装ドキュメントから学ぶほうが早い。商用プロダクトで実際に戦っているチームのノウハウが一次情報として出てくるためだ。
推奨リソースとハンズオン教材
6ヶ月ロードマップを回すために、段階別の推奨リソースを整理する。すべてを読み切る必要はなく、手元のアウトプットで詰まったタイミングでピンポイントに参照する使い方が実務的だ。
- 公式ドキュメント:OpenAI Platform、Anthropic、Google DeepMind。一次情報として常に最優先。
- Hugging Face:モデル/データセット/Transformersライブラリ。OSSモデルの挙動比較やタスク別ベンチマークの俯瞰に使う。
- 論文:Transformer(Attention Is All You Need)、RAG、Chain-of-Thought、Constitutional AI、推論モデル関連の代表論文は概要レベルで押さえる。
- 書籍:アプリ層中心なら『Designing Machine Learning Systems』、評価の理論寄りなら『Interpretable Machine Learning』。和書は改訂ペースが速いジャンルのため、出版日を必ず確認する。
- ハンズオン:OpenAI Cookbook、Anthropic の Prompt Library、Hugging Face のNLPコースはいずれも無料で、実行可能なコード付き。
- コミュニティ:Stack Overflow Developer Surveyで業界の技術採用動向を押さえつつ、GitHub TrendingでOSS動向を観察する。
個別の特定ベンダーやブートキャンプを推す書き方はあえて避けている。技術選定は自分のユースケース次第で、中立的な比較ができる視点を育てること自体が学習成果の一部だ。
学習の落とし穴と対処
独学・社内学習で陥りやすいパターンを4つ挙げる。いずれも「努力しているのに市場で通用する力が付かない」典型例だ。
落とし穴1:論文偏重で実装が回らない
arXivを毎日チェックして要旨を読むのが習慣化しているのに、自分の手元ではAPIをまともに叩けていない状態。論文は設計判断の引き出しを増やすには有効だが、実装感覚は手を動かさない限り付かない。対処は単純で、週の学習時間の少なくとも60%をコードとアウトプットに振り、論文は「実装で詰まった論点」を調べる道具として使う。
落とし穴2:汎用ベンチマーク偏重
MMLUやHumanEvalのスコアでモデルを選ぶ習慣が付くと、自分のユースケースでの性能との乖離に気付けなくなる。汎用ベンチは参考程度に留め、自分のタスクに特化した評価セットで選定するのが実務の原則。評価セットを作る習慣は月2〜3のプロンプト学習段階から前倒しで始めたい。
落とし穴3:評価不在でプロンプトを磨き続ける
プロンプトを主観で「良くなった気がする」レベルで回し続けるパターン。改善の因果関係が追えないため、半年経っても知見が蓄積しない。数値で比較する評価セットを先に作り、プロンプト変更の効果を必ず数値で語る癖を早い段階で身につける。
落とし穴4:本番運用スキップ
デモまでは作るが、監視・コスト最適化・セキュリティに一度も触れずに「LLMアプリが作れる」と自認してしまうケース。選考現場では運用経験の有無で評価が明確に分かれる。学習の最後の2ヶ月は、あえて運用目線の課題に時間を配分するのが差別化に繋がる。
学習成果をキャリアに換算する
学習で積み上げたスキルは、可視化しない限り市場には伝わらない。以下の3点を学習と並行で整えることをお勧めする。
- ポートフォリオ設計:月ごとに作ったアウトプットを、READMEに評価数値・設計判断・改善履歴まで書く。「動きます」ではなく「なぜこの設計を選び、どう計測したか」が読める状態を目指す。書き方のテンプレはITエンジニアのポートフォリオガイドにまとめている。
- GitHub:private中心の学習リポジトリを、機微情報を抜いた形で段階的にpublic化する。コミット粒度・PR運用・テストの有無で実務経験が透けて見えるため、短期のアウトプットを綺麗に積む意識が効く。職務経歴書との紐付けはGitHub経歴書ジェネレーターで可視化できる。
- OSS貢献:公式SDKのドキュメント改善、typo修正、Issue報告、小規模バグ修正からで十分。LLM領域は変化が速く、少しの貢献でもメンテナに認知されやすい。
ハイクラス転職で実際に評価されるスキル全体像はハイクラス転職で評価されるスキル、エージェントの使い分けはハイクラスITエンジニア向け転職エージェント比較で補完できる。LLM領域の市場相場は流動的なため、年収や希少性は幅表記で把握するのが安全だ。経済産業省のIT人材需給調査でも、先端IT人材の不足は継続的に指摘されており、市場としての追い風は当面続くと見られる。具体的なポジションと年収レンジは、ITエンジニア特化の転職サービス(例:TechGoなど)で現時点の求人を確認すると、学習後の着地点を現実的に設計しやすい。
まとめ
- LLMエンジニアのスキルは「基礎理解/アプリ実装/運用・評価」の3層に分解し、バランスよく積む。
- 6ヶ月ロードマップは「基礎 → プロンプト → RAG → Agent → 本番運用」の順序で、各月にアウトプットを対応させる。
- 評価セットを早期に作る習慣が、プロンプト・RAG・Agentすべてに通底する中核スキル。
- LangChain等のフレームワークは必須ではなく、公式SDKで素のAPIを理解してから抽象化の必要性を判断する。
- 論文偏重・汎用ベンチ偏重・評価不在・運用スキップの4つは独学の典型失敗パターン。アウトプット中心に回す。
- 学習成果はポートフォリオ・GitHub・OSS貢献で可視化して初めて市場価値になる。
(本記事は2026年4月時点の一般的な市場情報と公式ドキュメントをもとにした編集部の見解です。学習に必要な期間・到達点は個人のバックグラウンドにより大きく異なり、特定の成果を保証するものではありません。技術情報は各社公式ドキュメントの最新版をご確認ください)


