SRE(Site Reliability Engineer)およびプラットフォームエンジニアは、2026年のIT人材市場において最もレンジ上限が高い職種のひとつだ。理由は明快で、事業KPIへの影響(可用性・コスト・開発速度)が可視化しやすく、供給が需要に追いついていないからである。本記事では年代別・スキル軸別・企業タイプ別にレンジを整理し、インフラエンジニアからの移行ロードマップ、シニア・スタッフ級の到達条件まで踏み込む。情報源は厚生労働省の賃金構造基本統計調査、経済産業省のIT人材需給調査、Stack Overflow Developer Survey、CNCF Annual Survey、そしてTechGoの公式公表値に限定している。
この記事でわかること
- SRE/プラットフォームエンジニアの職域と、インフラ運用との違い
- 2026年時点の年代別・企業タイプ別の年収レンジ
- AWS/GCP・Kubernetes・Terraform・Observability・英語など、スキル軸ごとの年収差
- シニア/スタッフクラスに到達するために必要な条件
- インフラエンジニアからSREへ移行する際の具体的ロードマップ
- 年収を上げる5つの実務アクション
- よくある質問(FAQ)への実務的な回答
SRE/プラットフォームエンジニアの職域 — 「インフラ屋」ではない

まず押さえたいのは、SREとプラットフォームエンジニアは「従来のインフラエンジニア」の延長ではない、ということだ。職域の違いを理解しないと、同じスキルセットで転職活動をしても求人レンジを読み違える。
可用性エンジニアリング(Reliability)
SLI(Service Level Indicator)・SLO(Service Level Objective)・エラーバジェットを設計し、プロダクトの信頼性を数値で管理する領域。単に「落ちないようにする」のではなく、「どの程度落ちていいか」を事業側と合意形成し、エラーバジェットの消費状況に応じて開発速度と安定性のバランスを調整する。SRE特有の思考法で、Googleが提唱したSRE本以来の標準的な枠組みとなっている。
可観測性(Observability)
メトリクス・ログ・トレース・プロファイルの4柱を統合し、分散システムの内部状態を可視化する領域。OpenTelemetryによる計装、Prometheus/Grafana、Datadog、New Relic、Honeycombなどのツール選定と運用、インシデント発生時の原因特定を高速化するためのダッシュボード設計、アラート設計、ランブック整備まで含む。
キャパシティ・コスト最適化
クラウドコストの最適化、リソース予約、オートスケーリング設計、リザーブドインスタンス/Savings Plans/Committed Useの運用、FinOps文化の浸透までを担う領域。月額数千万円規模のクラウド支出を扱う事業会社では、数%のコスト削減が直接的な事業貢献として評価される。
開発者体験(Developer Experience / DevEx)
内部開発者プラットフォーム(Internal Developer Platform)の構築、CI/CDパイプライン整備、GitOps、セルフサービス型の環境払い出し、ポリシー・ガードレールの設計などを通じて、開発チームの生産性を引き上げる領域。「プラットフォームエンジニア」という職種名が広がった背景にある職域だ。
セキュリティ・コンプライアンス
IAM設計、ネットワーク分離、Secrets管理、脆弱性スキャン、監査ログ設計、コンテナ・サプライチェーンセキュリティなど、プラットフォーム横断のセキュリティ基盤を担う領域。金融・医療・公共系SaaSでは必須要件で、シニア以上で評価レンジが上振れしやすい。
この5つの職域の中で、自分がどこに軸足を置き、どこへ広げるかを言語化することがキャリア設計の起点になる。全部を1人でカバーする必要はなく、むしろ軸を定めた方がシニア以上の評価に繋がりやすい。
年代別の年収レンジ(2026年の目安)
以下のレンジは事業会社・SaaS・メガベンチャーのSRE/プラットフォームエンジニアで一般的に観測される目安で、Stack Overflow Developer Survey日本在住回答者の分布やCNCF Annual Surveyの参照、求人市場の観察をもとに編集部が整理した。
| 年代 | 経験年数の目安 | 年収レンジ | 期待される役割 |
|---|---|---|---|
| 20代前半 | 1〜3年目 | 420〜600万円 | 既存基盤の運用保守、監視対応、小規模なIaC変更、オンコール2次対応 |
| 20代後半 | 3〜6年目 | 550〜850万円 | IaCモジュール設計、監視・アラート設計、インシデント対応のリード、SLO設計支援 |
| 30代前半 | 6〜9年目 | 700〜1,100万円 | プラットフォーム全体設計、SLO設計主導、オンコール体制構築、コスト最適化プロジェクト |
| 30代後半 | 9〜13年目 | 900〜1,400万円 | シニアSRE/スタッフSRE、技術戦略立案、採用・組織設計、複数プロダクト横断の信頼性設計 |
| 40代 | 13年目以降 | 1,100〜1,800万円超 | プリンシパル/ディスティングイッシュ級、SRE組織全体のリード、CTO/VPoE候補 |
同年代のフロントエンド・バックエンドと比較して、SRE領域は上限側がやや高く出る傾向がある。理由は後述するが、クラウド・分散システム・大規模運用経験のある人材が国内で慢性的に不足していることが大きい。職種横断の相場感は2026年版 ITエンジニアの年収相場も参照してほしい。
スキル軸別の年収差 — どこで差が付くか
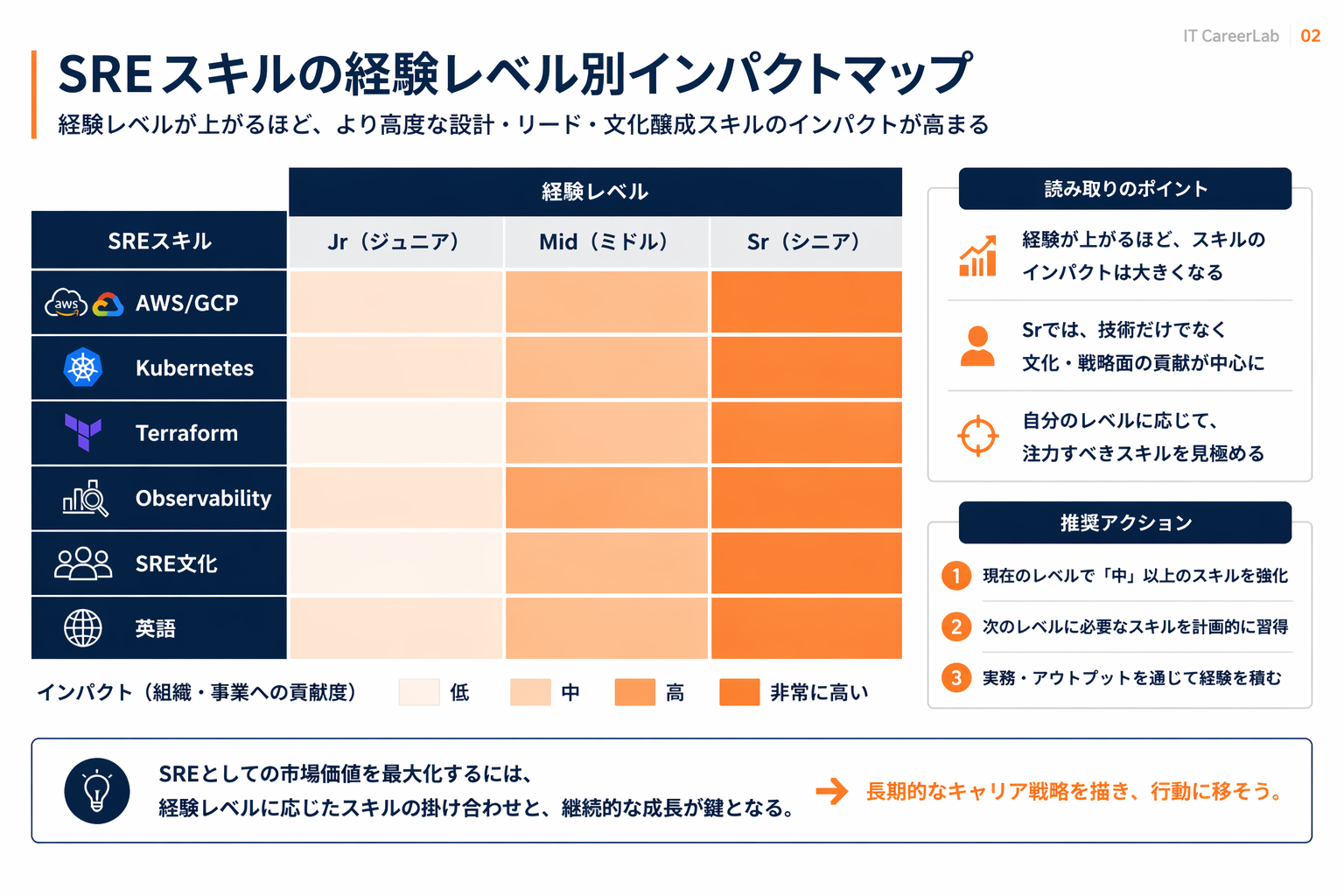
AWS/GCP/Azureの実運用深度
「触ったことがある」と「大規模プロダクションで設計した」の差が、SRE領域では年収に直結する。AWS Organizations設計、マルチアカウント戦略、ネットワーク設計(Transit Gateway・PrivateLink)、IAM権限分離、コスト配賦の実運用経験などは、シニア帯で強く評価される。GCPのProject階層設計、VPC Service Controls、Workload Identityなども同様だ。資格の優先順位はクラウド資格の優先順位で整理している。
Kubernetes(CNCF Cloud Native)
CNCF Annual Surveyが示す通り、Kubernetesはクラウドネイティブの事実上の標準として定着した。単にkubectlが使えるだけでは差がつかず、カスタムコントローラ設計、Operator開発、Helm/Kustomize/ArgoCDでのGitOps、マルチクラスタ戦略、ネットワークポリシー、セキュリティ(Pod Security Standards、OPA Gatekeeper)まで踏み込める経験がシニア評価に繋がる。
Terraform/Pulumi/OpenTofu(IaC)
Terraformのモジュール設計、Remote State管理、Policy as Code(Sentinel、OPA)、CI/CDでの適用パイプライン、リファクタリング戦略(State移行、Import)などの実務経験は、プラットフォーム設計の評価に直結する。2024年以降のOpenTofuへの関心も広がっており、IaCツールチョイスの設計判断を語れることも評価軸になる。
Observability(OpenTelemetry系)
OpenTelemetryの計装設計、Trace Contextの伝播、サンプリング戦略、Datadog/New Relic/Honeycomb/Grafanaの選定と運用、SLO/エラーバジェットダッシュボードの設計まで踏み込めるエンジニアは、2026年時点で希少性が高い。可観測性の設計は「どこにいくらコストをかけるか」の意思決定そのものであり、シニア以上で評価レンジが上振れしやすい。
SRE文化の浸透力
技術力だけではシニアに到達しない。SLI/SLO設計を事業側と合意形成する、エラーバジェットを開発チームと共有する、ポストモーテムを組織文化として定着させる、オンコール負担の公平化、といった「文化を作る力」がスタッフ級以上で評価される。コードではなく組織に対するレバレッジを出せるかが分岐点だ。
英語でのコミュニケーション
CNCF系OSSへの貢献、海外チームとのインシデント対応、グローバル企業でのオンコール輪番参加など、英語ができることで選択肢が広がる分野だ。外資系・グローバルチームのSREはレンジの上限が国内企業より1段高く、英語があれば年収上限を伸ばせる。海外テックキャリアの実務ガイドも参考にしてほしい。
企業タイプ別レンジ
| 企業タイプ | ミドル層の目安 | シニア層の目安 | 特徴・注意点 |
|---|---|---|---|
| 事業会社(国内SaaS・toC) | 600〜900万円 | 900〜1,300万円 | プロダクト成長に伴う信頼性投資で需要が安定。シニアで1,000万円超は現実的 |
| メガベンチャー | 700〜1,000万円 | 1,000〜1,500万円 | 大規模トラフィック経験が積める環境。等級上のSRE Staffで1,300万円超が射程 |
| 外資系テック | 900〜1,300万円 | 1,300〜2,200万円超 | 基本給+RSU+オンコール手当。シニアSRE/スタッフSREで国内企業と1段違うレンジ |
| 受託インフラ・クラウドMSP | 500〜750万円 | 750〜1,100万円 | 複数顧客の基盤を扱う経験が積める一方、個人年収の天井が案件単価で規定されやすい |
| スタートアップ | 550〜850万円+SO | 800〜1,200万円+SO | 1人目SREとして入ると裁量は大きいが、属人化・オンコール負担も集中しやすい |
受託インフラ・MSP出身からのキャリアチェンジは、事業会社・メガベンチャーへの移行で年収レンジが一段上がりやすい。逆にスタートアップで1人目SREを担う場合は、ストックオプション込みでの設計と、オンコール負担の明示的な交渉が持続可能性の鍵になる。
年収レンジが高いシニア/スタッフクラスの条件
1,200万円超のシニアSRE/スタッフSREに到達している人材が共通して持っている条件を整理する。個人の技術力だけでなく、組織へのレバレッジが評価軸の中心になる。
- プロダクション運用での大規模障害対応経験:月間億PV規模・数万QPS規模のシステムでインシデントを主導し、ポストモーテムを組織文化に定着させた実績。
- SLI/SLO設計の主導:事業側・開発チームとの合意形成を経て、エラーバジェット運用を組織に定着させた経験。
- コスト最適化の数値実績:月額数千万円〜億円規模のクラウド支出から、数千万円単位のコスト削減を実現した実績(リザーブド/Savings Plans戦略、アーキテクチャ見直し、FinOps文化浸透など)。
- Distributed Systems設計への踏み込み:分散トランザクション、Saga、CQRS、イベント駆動、キャッシュ整合性などの設計判断を担った経験。学習設計はシステム設計学習ロードマップを参照。
- 組織設計・採用への関与:SREチームの立ち上げ、オンコール体制の設計、SRE採用面接の設計、キャリアラダー策定などへの関与。
これらのうち3つ以上を具体的な数値・役割で職務経歴書に書けると、ハイクラス帯のスカウト・面接での通過率が大きく変わる。ハイクラス転職で評価されるスキルも併せて確認してほしい。
インフラエンジニアからSREへの移行ロードマップ
オンプレインフラ・ネットワーク運用・監視オペレーションの経験者が、SREへ移行するための6〜12ヶ月ロードマップを整理する。これは独学だけで完結する設計ではなく、社内・副業を含めた実務経験の獲得を前提としている。
ステージ1:基礎の土台作り(1〜3ヶ月目)
- AWS または GCP の基礎を一通り触る(アソシエイト相当の理解)
- Docker/コンテナの基礎を実務レベルで使える状態にする
- Terraformで小規模リソースをIaC化してみる
- LinuxとTCP/IPの基礎を改めて体系化しておく(既存の強みの再整理)
ステージ2:実務経験の獲得(4〜7ヶ月目)
- 社内のクラウド移行プロジェクトに手を挙げる、または副業で小規模なクラウド設計案件を請ける
- Kubernetesの基礎を押さえ、マネージドサービス(EKS/GKE/AKS)で実運用経験を作る
- 監視・アラート設計に関わり、PrometheusまたはDatadogでダッシュボードを設計する
- CI/CDパイプラインを1本最初から構築する経験を積む
ステージ3:SRE文化への接続(8〜12ヶ月目)
- SLI/SLO設計を小規模でも主導する、あるいはオブザーバーとして設計議論に入る
- ポストモーテムの主執筆・レビュー参加を経験する
- オンコール輪番に正規メンバーとして参加する
- 転職活動を視野に入れ、市場価値を測る(年収レンジチェッカーを活用)
この設計で重要なのは、座学だけで終わらせず「プロダクション環境での意思決定経験」を段階的に積むことだ。SREの市場価値は「本番で判断した経験」に強く依存する。
年収を上げる5つの実務アクション
- OSSへの貢献をポートフォリオ化する:CNCF系プロジェクトやクラウドSDKへの小さなPRから始め、GitHubを経歴の一部として見せられる状態にする。GitHub経歴書ジェネレーターで整理するとレジュメ提出が楽になる。
- 業務をOKR/SLOで数値化する:自分の担当領域の成果を、SLO達成率・MTTR短縮・コスト削減額など、数値で語れる形に変換する。数値がない職務経歴書はシニア評価に乗らない。
- コスト削減プロジェクトを主導する:クラウドコスト最適化はSRE/プラットフォーム領域でもっとも事業貢献が可視化しやすい領域。月額数百万円規模でも、率ではなく絶対額で書ける実績を作る。
- Distributed Systemsの設計力を磨く:分散トランザクション、イベント駆動、Saga、一貫性モデルなど、本番運用で効く設計知識を体系的に積む。システム設計学習ロードマップを参照。
- マネジメント/リード経験を段階的に作る:2〜3人の小チームからでよいので、採用面接への参加、オンボーディング設計、1on1運用など、組織レバレッジの経験を積む。マネジメント vs ICキャリアも参考にしてほしい。
転職時のレンジ最大化には、交渉設計が重要になる。エンジニアの年収交渉テクニックと市場価値診断の方法を組み合わせて、相場と個別評価の両軸で材料を揃えてほしい。ハイクラス帯のエージェント活用についてはハイクラスITエンジニア向け転職エージェント2026年版で整理しており、ITエンジニア特化で求人10,000件以上・年収交渉成功率100%(公式公表値)のTechGoのようなサービスを、交渉代行のレバレッジとして組み込む設計が現実的だ。
まとめ
- SRE/プラットフォームエンジニアは2026年のIT職種の中で上限レンジが特に高く、事業KPIへの影響の可視化しやすさと人材不足が背景にある。
- 年代別レンジは20代420〜850万円、30代700〜1,400万円、40代1,100〜1,800万円超が目安。
- シニア以上の評価軸は「大規模運用経験」「SLO設計」「コスト削減実績」「分散設計」「組織レバレッジ」の5条件。
- インフラエンジニアからの移行は6〜12ヶ月で実務経験を段階的に積む設計が現実的。
- AWS/GCP深度・Kubernetes・IaC・Observability・英語の5スキルが年収上限を規定する。
- 年収アップにはOSS・OKR化・コスト削減・設計力・マネジメントの5アクションが効く。
(本記事は一般的な市場情報をもとにした編集部の見解です。年収レンジは取材・公開レポート・求人市場の観察に基づく目安であり、個別の採用結果を保証するものではありません。本サイトはTechGoのアフィリエイトパートナーであり、リンク経由の申込で収益が発生する場合があります)